
Machine learning safety measures
/Yesterday in Functional but unsafe machine learning I wrote about how easy it is to build machine learning pipelines that yield bad predictions — a clear business risk. Today I want to look at some ways we might reduce this risk.
The diagram I shared yesterday tries to illustrate the idea that it’s easy to find a functional solution in machine learning, but only a few of those solutions are safe or fit for purpose. The question to ask is: what can we do about it?

You can’t make bad models safe, so there’s only one thing to do: shrink the field of functional models so that almost all of them are safe:
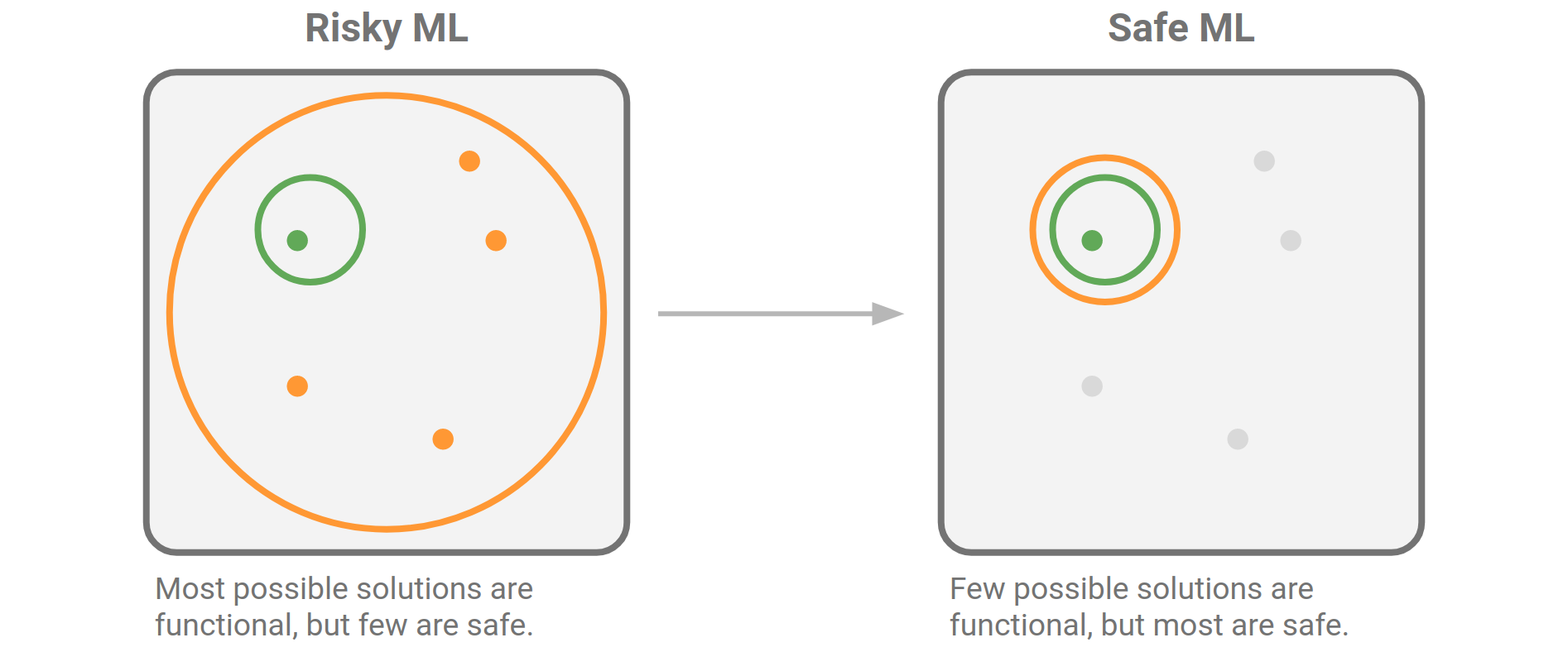
But before we do this any old way, we should ask why the orange circle is so big, and what we’re prepared to do to shrink it.
Part of the reason is that libraries like scikit-learn, and the Python ecosystem in general, are very easy to use and completely free. So it’s absolutely possible for any numerate person with a bit of training to make sophisticated machine learning models in a matter of minutes. This is a wonderful and powerful thing, unprecedented in history, and it’s part of why machine learning has been so hot for the last 6 or 8 years.
Given that we don’t want to lose this feature, what actions could we take to make it harder to build bad models? How can we improve over time like aviation has, and without premature regulation? Here are some ideas:
Fix and maintain the data pipeline (not the data!). We spend most of our time getting training and validation data straight, and it always makes a big difference to the outcomes. But we’re obsessed with fixing broken things (which is not sustainable), when we should be coping with them instead.
Raise the digital literacy rate: educate all scientists about machine learning and data-driven discovery. This process starts at grade school, but it must continue at university, through grad school, and at work. It’s not a ‘nice to have’, it’s essential to being a scientist in the 21st century.
Build software to support good practice. Many of the problems I’m talking about are quite easy to catch, or at least warn about, during the training and evaluation process. Unscaled features, class imbalance, correlated features, non-IID records, and so on. Education is essential, but software can help us notice and act on them.
Evolve quality assurance processes to detect ML smell. Organizations that are adopting (building or buying) machine learning (i.e. all of them), must get really good at sniffing out problems with machine learning projects — then fixing those problems — and at connecting practitioners so they can learng together and share good practice.
Recognizing that machine learning models are made from code, and must be subject to similar kinds of quality assurance. We should adopt habits such as testing, documentation, code review, continuous integration, and issue tracking for users to report bugs and request enhancements. We already know how to do these things.
I know some of this might sound like I’m advocating command and control, but that approach is not compatible with a lean, agile organization. So if you’re a CTO reading this, the fastest path to success here is not hiring a know-it-all Chief Data Officer from a cool tech giant, then brow-beating your data science practitioners with Best Practice documents. Instead, help your digital professionals create a high-functioning community of practice, connected both inside and outside the organizations, and support them learning and adapting together. Yes it takes longer, but it’s much more effective.
What do you think? Are people already doing these things? Do you see people using other strategies to reduce the risk of building poor machine learning models? Share your stories in the comments below.




 Except where noted, this content is licensed
Except where noted, this content is licensed