
x lines of Python: Ternary diagrams
/Difficulty rating: beginner-friendly
(I just realized that calling the more approachable tutorials ‘easy’ is perhaps not the most sympathetic way to put it. But I think this one is fairly approachable.)
If you’re new to Python, plotting is a great way to get used to data structures, and even syntax, because you get immediate visual feedback. Plots are just fun.
Data loading
The first thing is to load the data, which is contained in a Google Sheets spreadsheet. If you make a sheet public, it’s easy to make a URL that provides a CSV. Happily, the Python data management library pandas can read URLs directly, so loading the data is quite easy — the only slightly ugly thing is the long URL:
import pandas as pd uid = "1r7AYOFEw9RgU0QaagxkHuECvfoegQWp9spQtMV8XJGI" url = f"https://docs.google.com/spreadsheets/d/{uid}/export?format=csv" df = pd.read_csv(url)
This dataset contains results from point-counting 51 shallow marine sandstones from the Eocene Sobrarbe Formation. We’re going to plot normalized volume percentages of quartz grains, detrital carbonate grains, and undifferentiated matrix. Three parameters? Two degrees of freedom? Let’s make a ternary plot!
Data exploration
Once you have the data in pandas, and before getting to the triangular stuff, we should have a look at it. Seaborn, a popular statistical plotting library, has a nifty ‘pairplot’ which plots the numerical parameters against each other to help reveal patterns in the data. On the diagonal, it shows kernel density estimations to reveal the distribution of each property:
import seaborn as sns vars = ['Matrix', 'Quartz', 'Carbonate', 'Bioclasts', 'Authigenic'] sns.pairplot(df, vars=vars, hue='Facies Association')
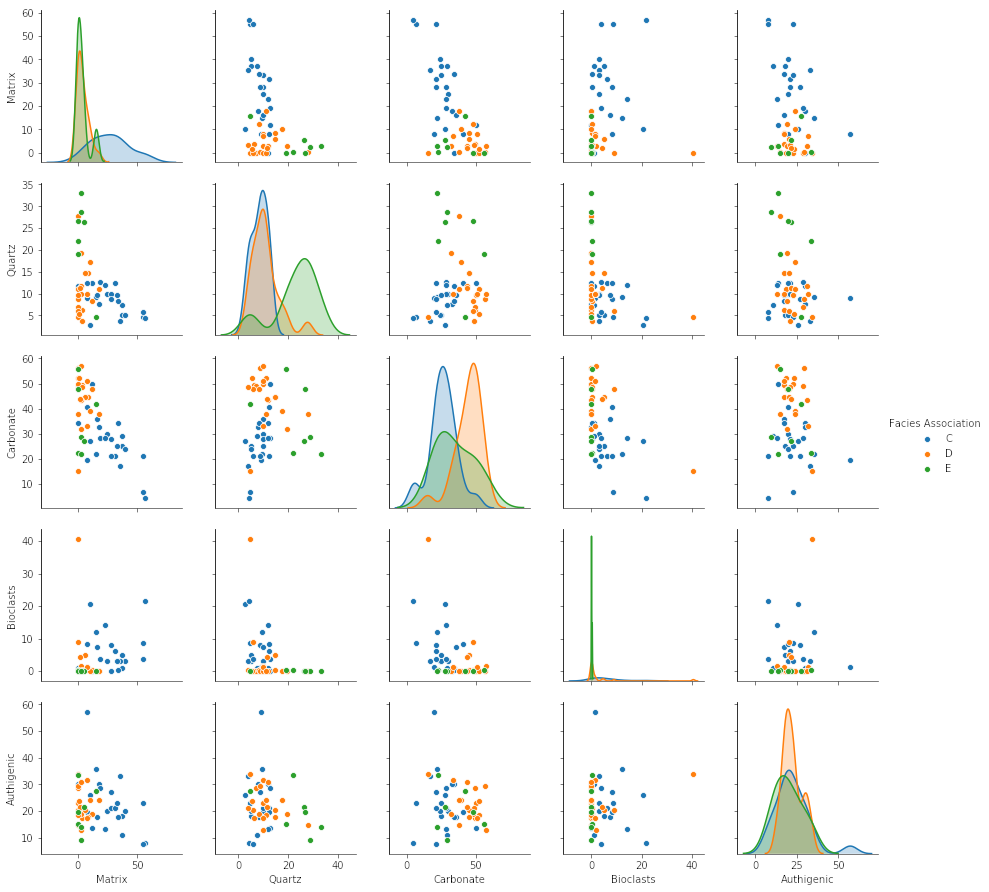
Normalization is fairly straightforward. For each column, e.g. df['Carbonate'], we make a new column, e.g. df['C'], which is normalized to the sum of the three components, given by df[cols].sum(axis=1):
cols = ['Carbonate', 'Quartz', 'Matrix'] for col in cols: df[col[0]] = df[col] * 100 / df[cols].sum(axis=1)
The ternary plot
For the ternary plot itself I’m using the python-ternary library, which is pretty hands-on in that most plots take quite a bit of code. But the upside of this is that you can do almost anything you want. (Theres one other option for Python, the ever-reliable plotly, and there’s a solid-looking package for R too in ggtern.)
We just need a few lines of plotting code (left) to pull a ternary diagram (right) together.
fig, tax = ternary.figure(scale=100) fig.set_size_inches(5, 4.5) tax.scatter(df[['M', 'Q', 'C']].values) tax.gridlines(multiple=20) tax.get_axes().axis('off')
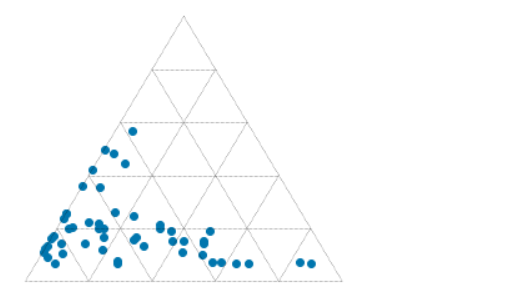
But here you see what I mean about this being quite a low-level library: each element of the plot has to be added explicitly. So if we want axis labels, titles, and other annotations, we need more code… all of which is laid out in the accompanying notebook. You can download this from GitHub, or run it right now, right in your browser, with these links:
![]() Run the accompanying notebook in MyBinder
Run the accompanying notebook in MyBinder
![]() Run the notebook in Google Colaboratory (note you need to install
Run the notebook in Google Colaboratory (note you need to install python-ternary)
Give it a go, and have fun making your own ternary plots in Python! Share them on LinkedIn or Twitter.

Quartz, carbonate and matrix quantities (normalized to 100%) for 51 calcareous sandstones from the Eocene Sobrarbe Formation. The ternary plot was made with python-ternary library for Python and matplotlib.




 Except where noted, this content is licensed
Except where noted, this content is licensed