
Comparing regressors
/There are several really nice comparisons between various algorithms in the Scikit-Learn documentation. The most famous, and useful, one is probably the classifier comparison:
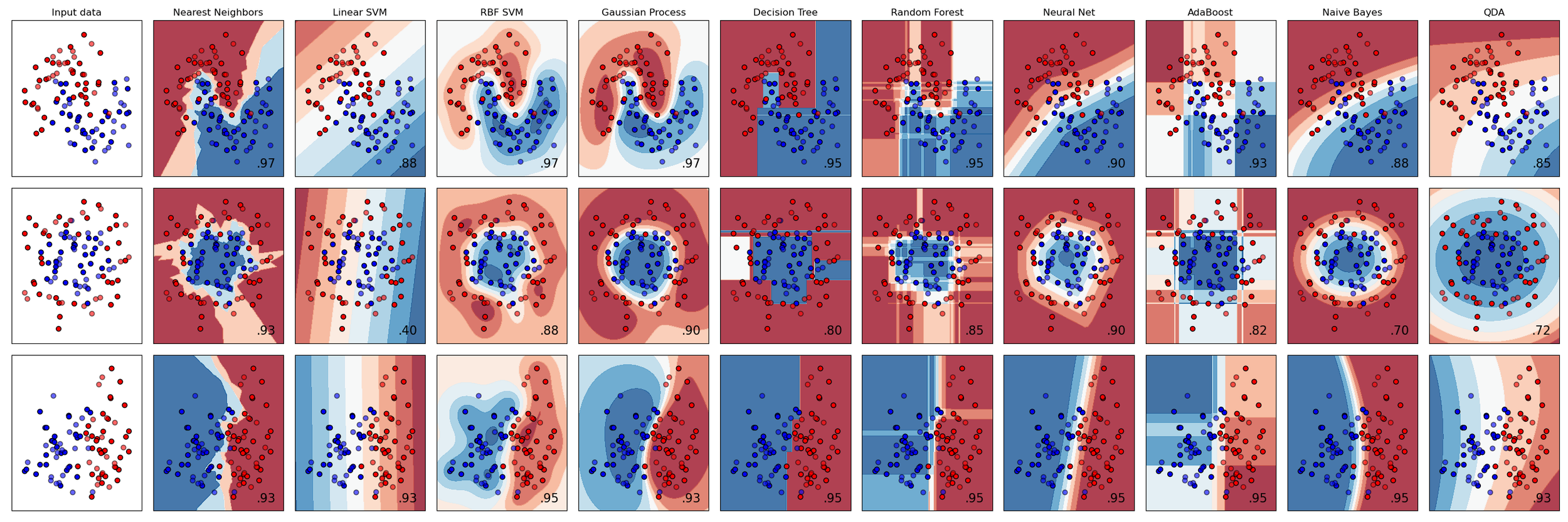
A comparison of classification algorithms. Each row is a different dataset; each column (except the first) is a different classifier, each trying to separate the blue and red points. The accuracy score of each classifier is show in the lower right corner of each plot. There’s so much to look at in this one plot!
There’s also a very nice clustering algorithm comparison, and this anomaly detection comparison. As usual with awesome open source software packages like Scikit-Learn, the really wonderful thing is that all the source code is right there so you can hack these things to show your own data.
What about regression?
Regression problems are the other major kind of machine learning task. If the thing you’re trying to predict is not a category (like ‘blue’ or ‘red’, as above) but a continuous property (like porosity, say), then you’re looking at a regression problem.
I wondered what a comparison plot for the various regressors in Scikit-Learn would look like. I couldn’t find one, so I made one. I made up three one-dimensional datasets — one linear, one polynomial, and one periodic. Then I tried predicting each one with various different model types, from linear regression to a deep neural network. Here’s version 1 (well, 0.1 really) of my script; feel free to adapt and improve it!
Here’s the plot it produces:
A comparison of most of the regressors in scikit-learn, made with this script. The red lines are unregularized models; the blue have regularization. The pale points are the validation data. The small numbers in each plot are RMS error (lower is better!).
I think this plot repays careful study. Notice the smoothing effect of regularization. See how tree-based methods result in discretized predictions, and kernel-based ones are pretty horrible at extrapolation.
I’m 100% open to feedback on ways to improve this plot… or please improve it and show me how it goes!


























































 Except where noted, this content is licensed
Except where noted, this content is licensed