
Machines can read too
/The energy industry has a lot of catching up to do. Humanity is faced with difficult, pressing problems in energy production and usage, yet our industry remains as secretive and proprietary as ever. One rich source of innovation we are seriously under-utilizing is the Internet. You have probably heard of it.
Machine experience design

Web sites are just the front-end of the web. Humans have particular needs when they read web pages — attractive design, clear navigation, etc. These needs are researched and described by the rapidly growing field of user experience design, often called UX. (Yes, the ways in which your intranet pages need fixing are well understood, just not by your IT department!)
But the web has a back-end too. Rather than being for human readers, the back-end is for machines. Just like human readers, machines—other computers—also have particular needs: structured data, and a way to make queries. Why do machines need to read the web? Because the web is full of data, and data makes the world go round.
So website administrators need to think about machine experience design too. As well as providing beautiful web pages for humans to read, they should provide widely-accepted machine-readable format such as JSON or XML, and a way to make queries.
What can we do with the machine-readable web?
The beauty of the machine-readable web, sometimes called the semantic web, or Web 3.0, is that developers can build meta-services on it. For example, a website like hipmunk.com that finds the best flights, wherever they are. Or a service that provides charts, given some data or a function. Or a mobile app that knows where to get the oil price.
In the machine-readable web, you could do things like:
- Write a program to analyse bibliographic data from SEG, SPE and AAPG.
- Build a mobile app to grab log mnemonics info from SLB's, HAL's, and BHI's catalogs.
- Grab course info from AAPG, PetroSkills, and Nautilus to help people find training they need.
Most wikis have a public application programming interface, giving direct, machine-friendly access to the wiki's database. Here are two views of one wiki page — click on the images to see the pages:
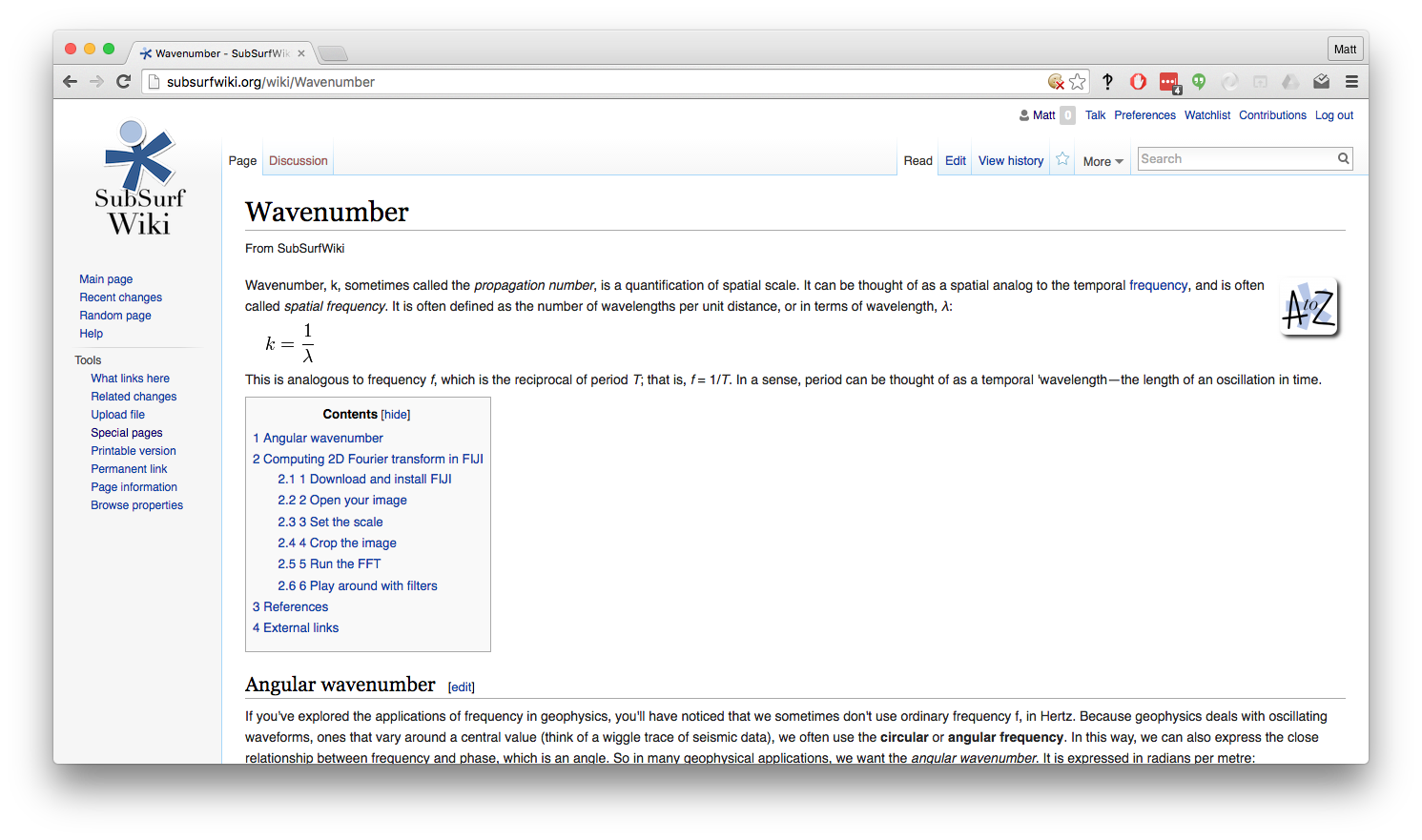

At SEG last year, I suggested to a course provider that they might consider offering machine access to their course catalog—so that developers can build services that use their course information and thus send them more students. They said, "Don't worry, we're building better search tools for our users." Sigh.
In this industry, everyone wants to own their own portal, and tends to be selfish about their data and their users. The problem is that you don't know who your users are, or rather who they could be. You don't know what they will want to do with your data. If you let them, they might create unimagined value for you—as hipmunk.com does for airlines with reasonable prices, good schedules, and in-flight Wi-Fi.
I can't wait for the Internet revolution to hit this industry. I just hope I'm still alive.




 Except where noted, this content is licensed
Except where noted, this content is licensed