
Machine learning and analytics in geoscience
/
We're at EAGE in Paris. I'm sitting in a corner of the exhibition because the power is out in the main hall, so all the talks for the afternoon have been postponed. The poor EAGE team must be beside themselves, I feel for them. (Note to future event organizers: white boards!)
Yesterday Diego, Evan, and I — along with lots of hackathon participants — were at the Data Science for Geosciences workshop, an all-day machine learning fest. The session was chaired by Cyril Agut (Total), Marianne Cuif-Sjostrand (Total), Florence Delprat-Jannaud (IFPEN), and Noalwenn Dubos-Sallée (IFPEN), and they had assembled a good programme, with quite a bit of variety.
Michel Lutz, Group Data Officer at Total, and adjunct at École des Mines de Saint-Étienne, gave a talk entitled, Data science & application to geosciences: an introduction. It was high-level but thoughtful, and such glimpses into large companies are always interesting. The company seems to have a mature data science strategy, and a well-developed technology stack. Henri Blondelle (AgileDD) asked about open data at the end, and Michel somewhat sidestepped on specifics, but at least conceded that the company could do more in open source code, if not data.
Infrastructure, big data, and IoT
Next we heard a set of talks about the infrastructure aspect of big (really big) data.
Alan Smith of Luchelan told the group about some negative experiences with Hadoop and seismic data (though it didn't seem to me that his problems were insoluble since I know of several projects that use it), and the realization that sometimes you just need fast infrastructure and custom software.
Hadi Jamali-Rad of Shell followed with an IoT story from the field. He had deployed a large number of wireless seismic sensors around a village in Holland, then tested various aspects of the communication system to answer questions like, what's the packet loss rate when you collect data from the nodes? What about from a balloon stationed over the site?
Duncan Irving of Teradata asked, Why aren't we [in geoscience] doing live analytics on 100PB of live data like eBay? His hypothesis is that IT organizations in oil and gas failed to keep up with key developments in data analytics, so now there's a crisis of sorts and we need to change how we handle our processes and culture around big data.
Machine learning
We shifted gears a bit after lunch. I started with a characteristically meta talk about how I think our community can help ensure that our research and practice in this domain leads to good places as soon as possible. I'll record it and post it soon.
Nicolas Audebert of ONERA/IRISA presented a nice application of a 3D convolutional neural network (CNN) to the segmentation and classification of hyperspectral aerial photography. His images have between about 100 and 400 channels, and he finds that CNNs reduce error rates by up to about 50% (compared to an SVM) on noisy or complex images.
Henri Blondelle of Agile Data Decisions talked about his experience of the CDA's unstructured data challenge of 2016. About 80% of the dataset is unstructured (e.g. folders of PDFs and TIFFs), and Henri's vision is to transform 80% of that into structured data, using tools like AgileDD's IQC to do OCR and heuristic labeling.
Irina Emelyanova of CSIRO provided another case study: unsupervised e-facies prediction using various types of clustering, from K-means to some interesting variants of self-organizing maps. It was refreshing to see someone revealing a lot of the details of their implementation.
Jan Limbeck, a research scientist at Shell wrapped up the session with an overview of Shell's activities around big data and machine learning, as they prepare for exabytes. He mentioned the Mauricio Araya-Polo et al. paper on deep learning in seismic shot gathers in the special March issue of The Leading Edge — clearly it's easiest to talk about things they've already published. He also listed a lot of Shell's machine learning projects (frac optimization, knowledge graphs, reservoir simulation, etc), but there's no way to know what state they are in or what their chances of success are.
As well as all the 9 talks, there were 13 posters, about a third of which were on infrastructure stuff, with the rest providing more case studies. Unfortunately, I didn't get the chance to look at them in any detail, but I appreciated the organizers making time for discussion around the posters. If they'd also allowed more physical space for the discussion it could have been awesome.
Analytics!
After hearing about Mentimeter from Chris Jackson I took the opportunity to try it out on the audience. Here are the results, I think they are fairly self-explanatory...
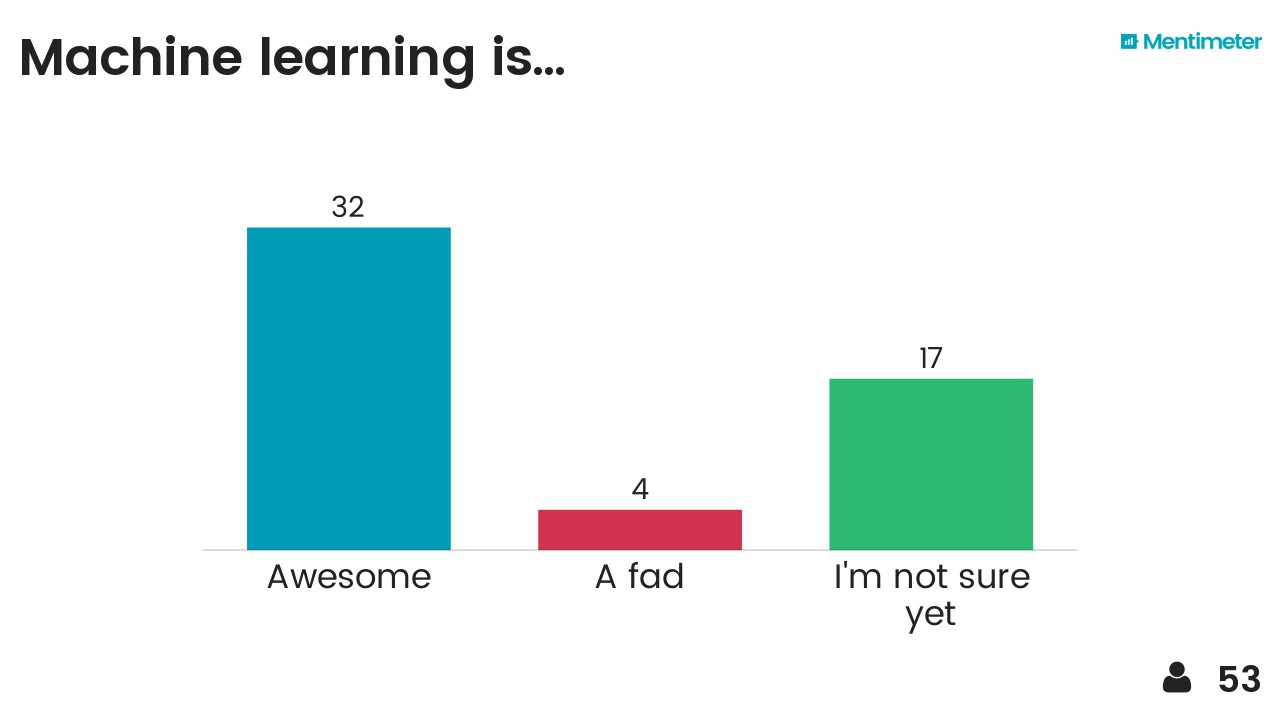
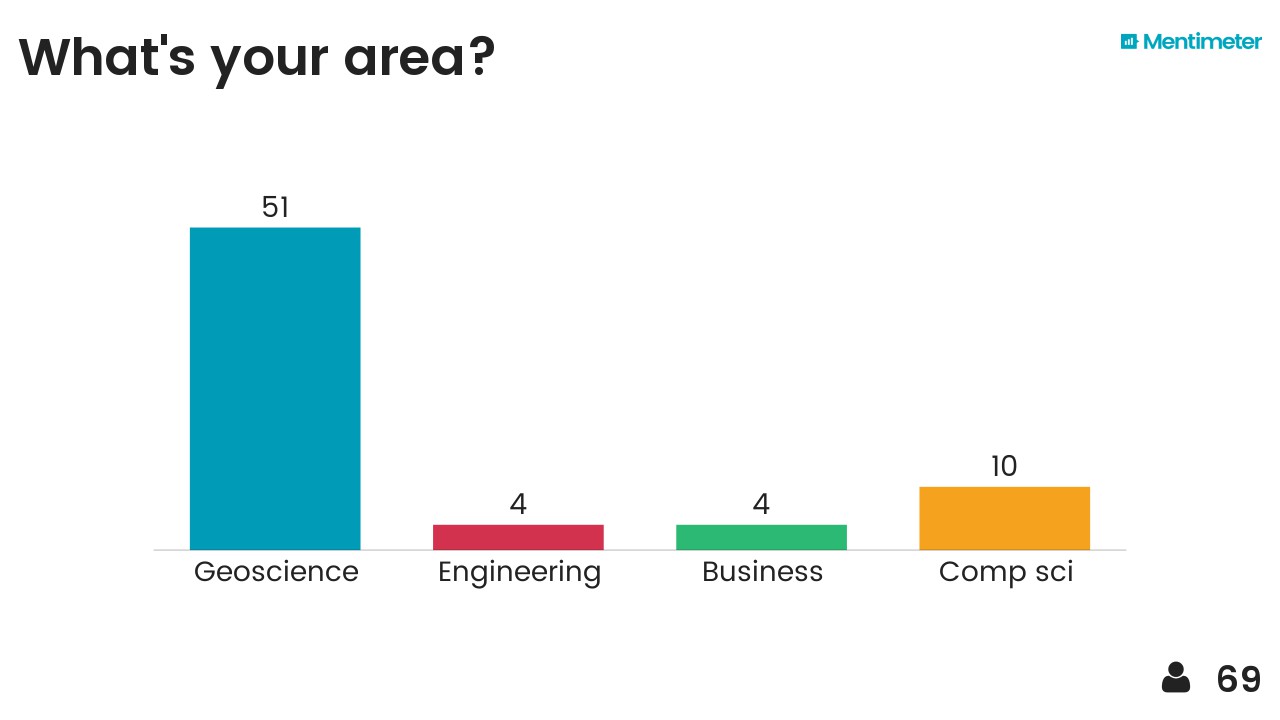
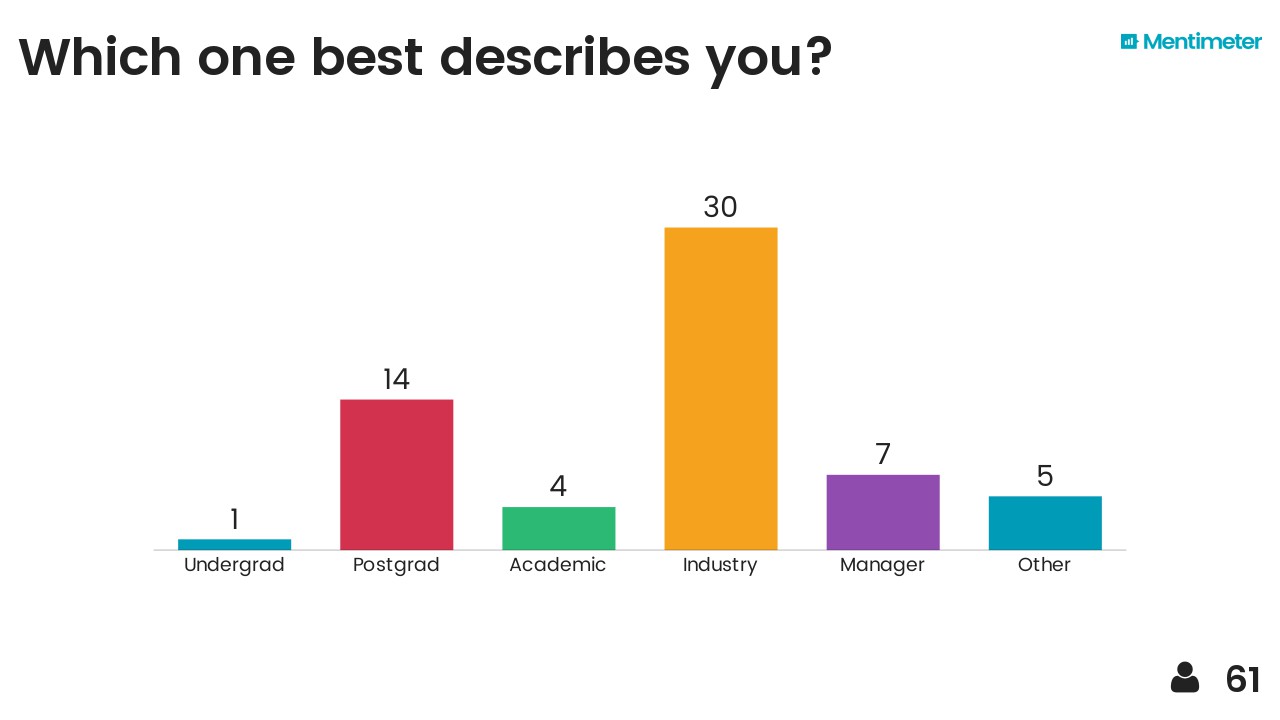

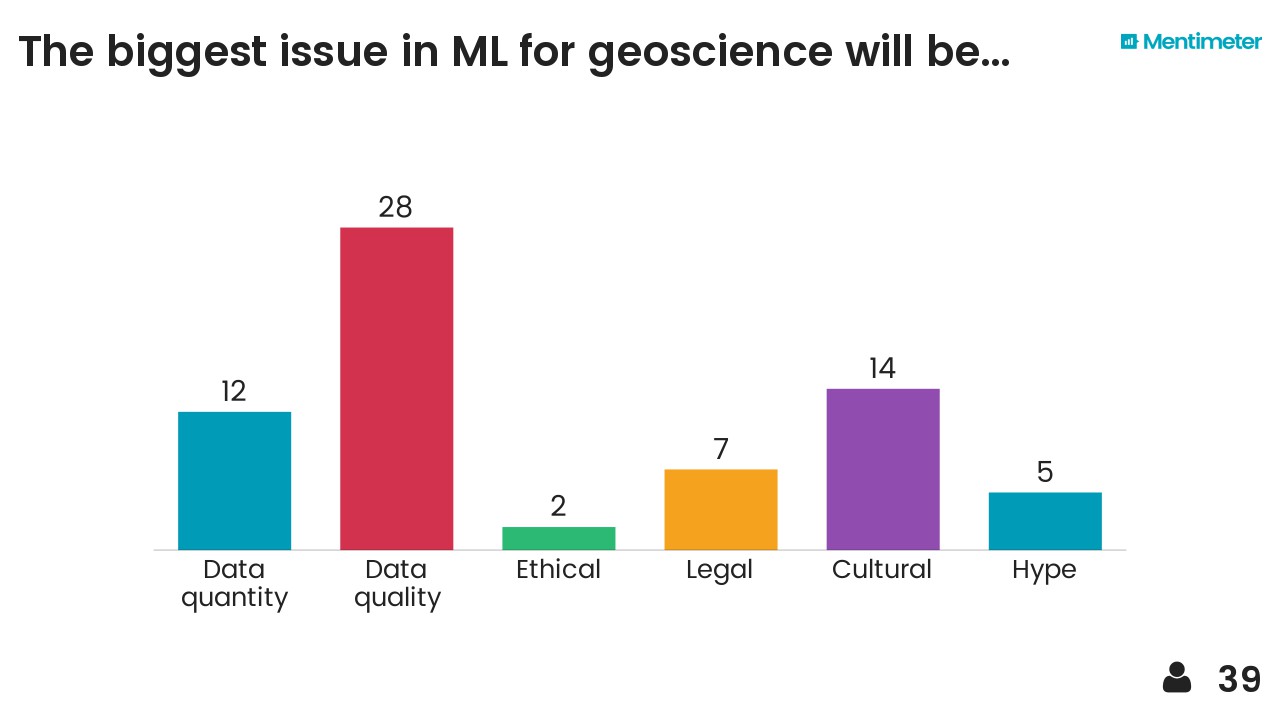
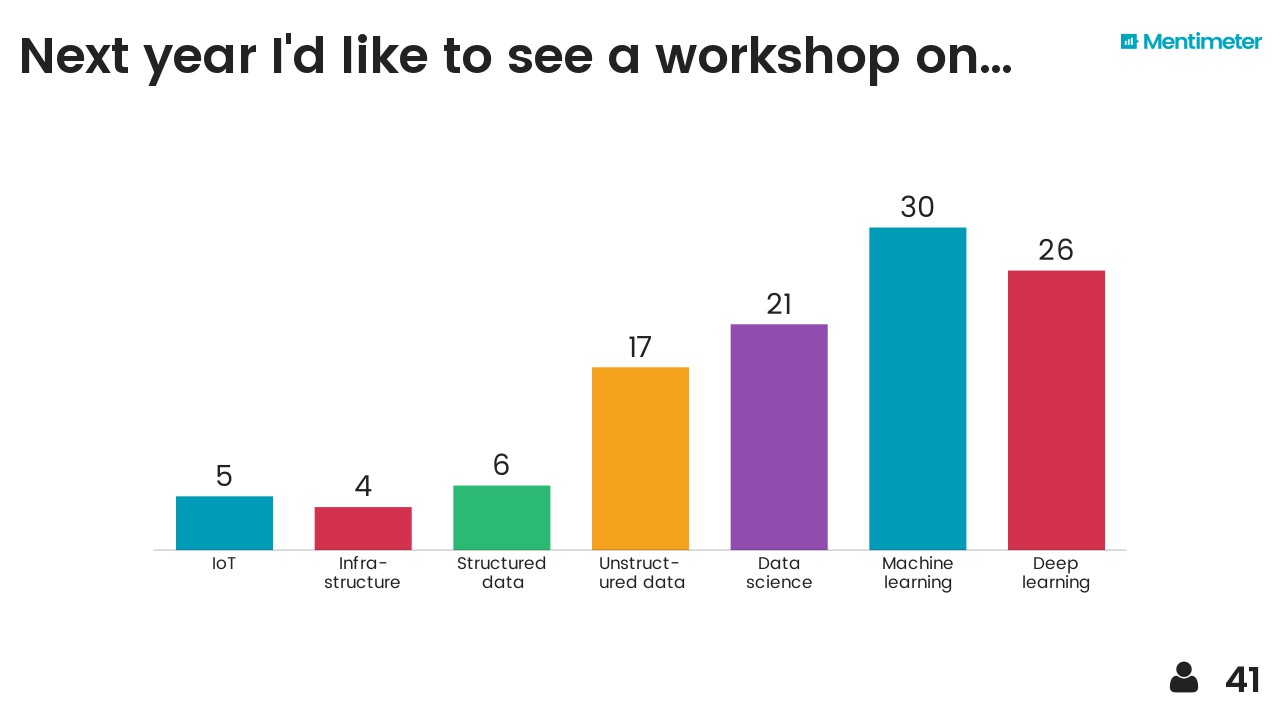
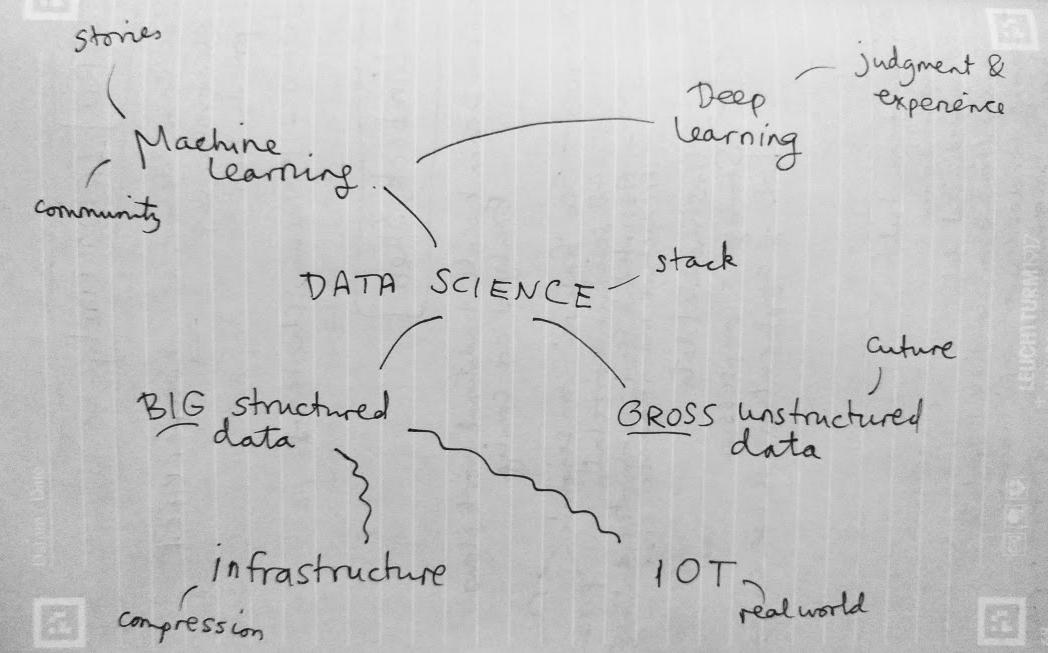
I also threw in the mindmap I drew at the end as a sort of summary. The vertical axis represents something like'abstraction' or 'time' (in a workflow sense) and I think each layer depends somewhat on those beneath it. It probably makes sense to no-one but me.
Breakout!
It seems clear that 2017 is the breakout year for machine learning in petroleum geoscience, and in petroleum in general. If your company or institution has not yet gone beyond "watching" or "thinking about" data science and machine learning, then it is falling behind by a little more every day, and it has been for at least a year. Now's the time to choose if you want to be part of what happens next, or a victim of it.




 Except where noted, this content is licensed
Except where noted, this content is licensed