
Subsurface Hackathon project round-up, part 1
/
The dust has settled from the Hackathon in Paris two weeks ago. Been there, done that, came home with the T-shirt.
In the same random order they presented their 4-minute demos to our panel of esteemed judges, I present a (very) abbreviated round-up of what the teams made together over the course of the weekend. With the exception of a few teams who managed to spontaneously nucleate before the hackathon, most of these teams were comprised of people who had never met each other before the event.
Just let that sink in for a second: teams of mostly mutual strangers built 13 legit machine-learning-based geoscience applications in one weekend.

Log Healer
An automated well log management system
Team Un-well Loggers: James Wanstall (Glencore), Niket Doshi (Teradata), Joseph Taylor (Teradata), Duncan Irving (Teradata), Jane McConnell (Teradata).
Tech: Kylo (NiFi, HDFS, Hive, Spark)
If you're working with well logs, and if you've got lots of them, you've almost certainly got gaps or inaccuracies from curve to curve and from well to well. The team's scalable, automated well-log file management system Log Healer computes missing logs and heals broken ones. Amazing.

An early result from Team Janus. The image on the left is ground truth, that on the right is predicted. Many of the features are present. Not bad for v0.1!
Meaningful cross sections from well logs
Team Janus: Daniel Buse, Johannes Camin, Paul Gabriel, Powei Huang, Fabian Kampe (all from GiGa Infosystems)
The team built an elegant machine learning workflow to attack the very hard problem of creating geologically realistic cross-section from well logs. The validation algorithm compares pixels to score the result.

Think Section's mindblowing photomicrograph labeling tool can also make novel camouflage patterns.
Paint-by-numbers on digital thin sections
Team Think Section: Diego Castaneda (Agile*), Brendon Hall (Enthought), Roeland Nieboer (Fugro), Jan Niederau (RWTH Aachen), Simon Virgo (RWTH Aachen)
Tech: Python (Scikit Learn, Scikit Image, Flask, NumPy, SciPy, Pandas), AWS for hosting app & Jupyter server.
Description: Mineral classification and point-counting on thin sections can be an incredibly tedious and time consuming task. Team Think Section trained a model to segregate, classify, and label mineral grains in 200GB of high-resolution multi-polarization-angle photomicrographs.
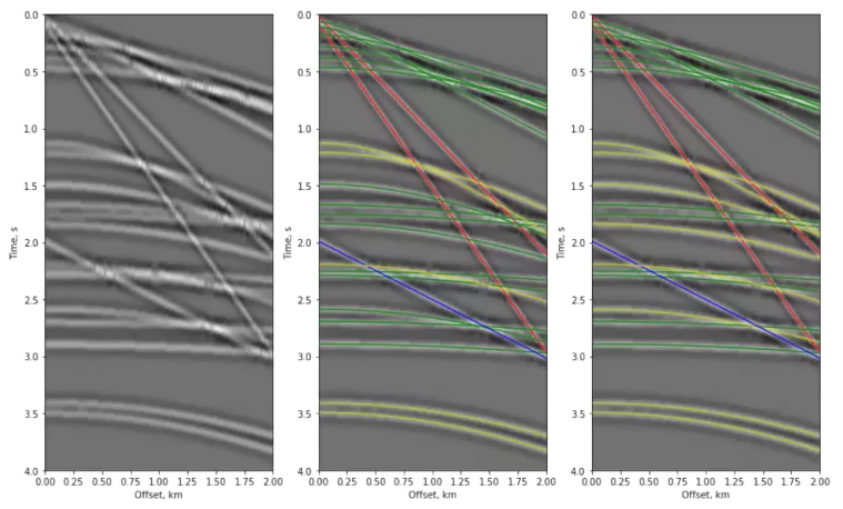
Team Classy's super-impressive shot gather seismic event Detection technology. Left: synthetic gather. Middle: predicted labels. Right: truth.
Event detection on seismic shot gathers
Team Classy: Princy Ikotoko Ndong (EOST), Anna Lim (NTNU), Yuriy Ivanov (NTNU), Song Hou (CGG), Justin Gosses (Valador).
Tech: Python (NumPy, Matplotlib), Jupyter notebooks.
The team created an AI which identifies and labels different events on a shot gather image. It can find direct waves, reflections, multiples or coherent noise. It uses a support vector machine for classification, and is simple and fast.

model2seismic: An entirely new way to do modeling and inversion. Take note: the neural network that made this image knows no physics.
Forward and inverse modeling without the physics
Team GANsters - Lukas Mosser (Imperial), Wouter Kimman (Meridian), Jesper Dramsch (Copenhagen), Alfredo de la Fuente (Wolfram), Steve Purves (Euclidity)
Tech: PyNoddy, homegrown Python ML tools.
The GANsters created a deep-learning image-translation-based seismic inversion and forward modelling system. I urge you to go and look at their project on model2seismic. If it doesn't give you goosebumps, you are geophysically inert.

Team Pick Pick Log
Machine learning for for stratigraphic interpretation
Team Pick Pick LOG - Antoine Vanbesien (EOST), Fidèle Degni (Mines St-Étienne), Massinissa Mesbahi (Pau), Natsuki Gunji (Mines St-Étienne), Cédric Menut (EOST).
This team of data science and geoscience undergrads attacked an automated stratigraphic interpretation task. They used supervised learning to determine lithology from well logs in Alberta's Athabasca play, then attempted to teach their AI to pick stratigraphic tops. Impressive!
Pretty amazing, huh? The power of the hackathon to bring a project from barely-even-an-idea to actual-working-code is remarkable! And we're not even halfway through the teams: tomorrow I'll describe the other seven projects.





























 Except where noted, this content is licensed
Except where noted, this content is licensed