
Impact structures in seismic
/I saw this lovely tweet from PGS yesterday:
Our basin studies team spotted this on fast-track imaging from Republic of Guinea. A 7.5 km diameter depression, with no salt or mobile shale, nor dissolution of fluid escape. We interpreted the structure as a complex meteorite impact crater. https://t.co/Z4TUOtsv54 #meteorite pic.twitter.com/hScJ31SoE3
— PGS (@PGSNews) August 1, 2019
Kudos to them for sharing this. It’s always great to see seismic data and interpretations on Twitter — especially of weird things. And impact structures are just cool. I’ve interpreted them in seismic myself. Then uninterpreted them.
I wish PGS were able to post a little more here, like a vertical profile, maybe a timeslice. I’m sure there would be tons of debate if we could see more. But not all things are possible when it comes to commercial seismic data.
It’s crazy to say more about it without more data (one-line interpretation, yada yada). So here’s what I think.
Impact craters are rare
There are at least two important things to think about when considering an interpretation:
How well does this match the model? (In this case, how much does it look like an impact structure?)
How likely are we to see an instance of this model in this dataset? (What’s the base rate of impact structures here?)
Interpreters often forget about the second part. (There’s another part too: How reliable are my interpretations? Let’s leave that for another day, but you can read Bond et al. 2007 as homework if you like.)
The problem is that impact structures, or astroblemes, are pretty rare on Earth. The atmosphere takes care of most would-be meteorites, and then there’s the oceans, weather, tectonics and so on. The result is that the earth’s record of surface events is quite irregular compared to, say, the moon’s. But they certainly exist, and occasionally pop up in seismic data.
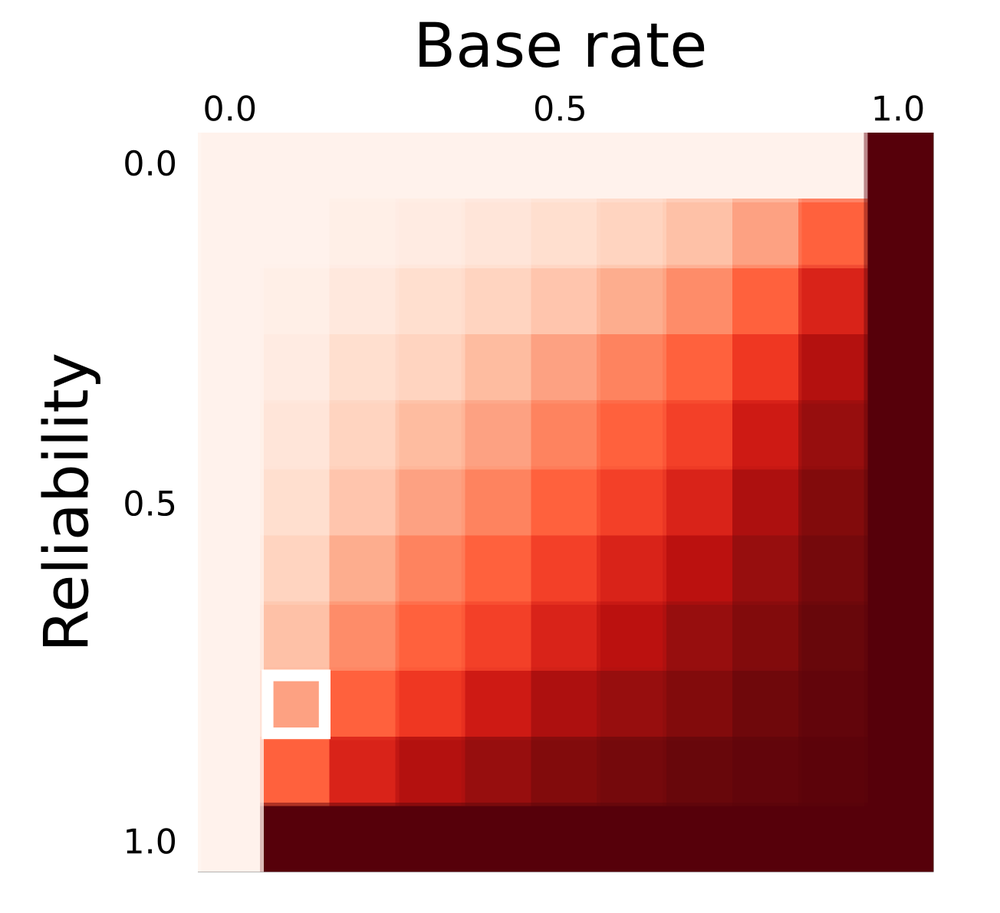
In my 2011 post Reliable predictions of unlikely geology, I described how skeptical we have to be when predicting rare things (‘wotsits’). Bayes’ theorem tells us that we must modify our assigned probability (let’s say I’m 80% sure it’s a wotsit) with the prior probability (let’s pretend a 1% a priori chance of there being a wotsit in my dataset). Here’s the maths:
\( \ \ \ P = \frac{0.8 \times 0.01}{0.8 \times 0.01\ +\ 0.2 \times 0.99} = 0.0388 \)
In other words, the conditional probability of the feature being a rare wotsit, given my 80%-sure interpretation, is 0.0388 or just under 4%.
As cool as it would be to find a rare wotsit, I probably need a back-up hypothesis. Now, what’s that base rate for astroblemes? (Spoiler: it’s much less than 1%.)
Just how rare are astroblemes?
First things first. If you’re interpreting circular structures in seismic, you need to read Simon Stewart’s paper on the subject (Stewart 1999), and his follow-up impact crater paper (Stewart 2003), which expands on the topic. Notwithstanding Stewart’s disputed interpretation of the Silverpit not-a-crater structure in the North Sea, these two papers are two of my favourites.
According to Stewart, the probability P of encountering r craters of diameter d or more in an area A over a time period t years is given by:
\( \ \ \ P(r) = \mathrm{e}^{-\lambda A}\frac{(\lambda A)^r}{r!} \)
where
\( \ \ \ \lambda = t n \)
and
\( \ \ \ \log n = - (11.67 \pm 0.21) - (2.01 \pm 0.13) \log d \)

We can use these equations to compute the probability plot on the right. It shows the probability of encountering an astrobleme of a given diameter on a 2400 km² seismic survey spanning the Phanerozoic. (This doesn’t take into account anything to do with preservation or detection.) I’ve estimated that survey size from PGS’s tweet, and I’ve highlighted the 7.5 km diameter they mentioned. The probability is very small: about 0.00025. So Bayes tells us that an 80%-confident interpretation has a conditional probability of about 0.001. One in a thousand.
Here’s the Jupyter notebook I used to make that chart using Python.
So what?
My point here isn’t to claim that this structure is not an astrobleme. I haven’t seen the data, I’ve no idea. The PGS team mentioned that they considered the possiblity of influence by salt or shale, and fluid escape, and rejected these based on the evidence.
My point is to remind interpreters that when your conclusion is that something is rare, you need commensurately more and better evidence to support the claim. And it’s even more important than usual to have multiple working hypotheses.
Last thing: if I were PGS and this was my data (i.e. not a client’s), I’d release a little cube (anonymized, time-shifted, bit-reduced, whatever) to the community and enjoy the engagement and publicity. With a proper license, obviously.
References
Hughes, D, 1998, The mass distribution of the crater-producing bodies. In Meteorites: Flux with time and impact effects, Geological Society of London Special Publication 140, 31–42.
Davis, J, 1986, Statistics and data analysis in geology, John Wiley & Sons, New York.
Stewart, SA (1999). Seismic interpretation of circular geological structures. Petroleum Geoscience 5, p 273–285.
Stewart, SA (2003). How will we recognize buried impact craters in terrestrial sedimentary basins? Geology 31 (11), p 929–932.
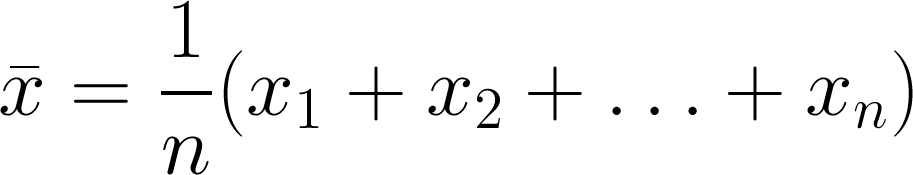










 Except where noted, this content is licensed
Except where noted, this content is licensed