
Cross plots: a non-answer
/On Monday I asked whether we should make crossplots according to statistical rules or natural rules. There was some fun discussion, and some awesome computation from Henry Herrera, and a couple of gems:
Physics likes math, but math doesn't care about physics — @jeffersonite
But... when I consider the intercept point I cannot possibly imagine a rock that has high porosity and zero impedance — Matteo Niccoli, aka @My_Carta
I tried asking on Stack Overflow once, but didn’t really get to the bottom of it, or perhaps I just wasn't convinced. The consensus seems to be that the statistical answer is to put porosity on y-axis, because that way you minimize the prediction error on porosity. But I feel—and this is just my flaky intuition talking—like this fails to represent nature (whatever that means) and so maybe that error reduction is spurious somehow.
Reversing the plot to what I think of as the natural, causation-respecting plot may not be that unreasonable. It's effectively the same as reducing the error on what was x (that is, impedance), instead of y. Since impedance is our measured data, we could say this regression respects the measured data more than the statistical, non-causation-respecting plot.
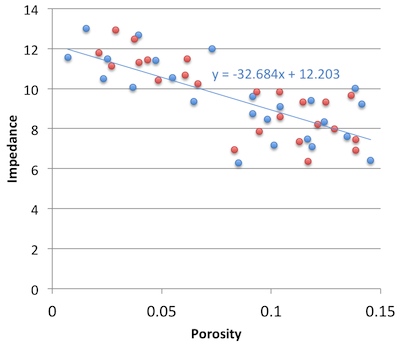 So must we choose? Minimize the error on the prediction, or minimize the error on the predictor. Let's see. In the plot on the right, I used the two methods to predict porosity at the red points from the blue. That is, I did the regression on the blue points; the red points are my blind data (new wells, perhaps). Surprisingly, the statistical method gives an RMS error of 0.034, the natural method 0.023. So my intuition is vindicated!
So must we choose? Minimize the error on the prediction, or minimize the error on the predictor. Let's see. In the plot on the right, I used the two methods to predict porosity at the red points from the blue. That is, I did the regression on the blue points; the red points are my blind data (new wells, perhaps). Surprisingly, the statistical method gives an RMS error of 0.034, the natural method 0.023. So my intuition is vindicated!
Unfortunately if I reverse the datasets and instead model the red points, then predict the blue, the effect is also reversed: the statistical method does better with 0.029 instead of 0.034. So my intuition is wounded once more, and limps off for an early bath.
Irreducible error?
Here's what I think: there's an irreducible error of prediction. We can beg, borrow or steal error from one variable, but then it goes on the other. It's reminiscent of Heisenberg's uncertainty principle, but in this case, we can't have arbitrarily precise forecasts from imperfectly correlated data. So what can we do? Pick a method, justify it to yourself, test your assumptions, and then be consistent. And report your errors at every step.
I'm reminded of the adage 'Correlation does not equal causation.' Indeed. And, to borrow @jeffersonite's phrase, it seems correlation also does not care about causation.

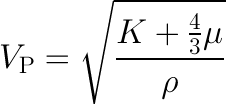




 Except where noted, this content is licensed
Except where noted, this content is licensed