A puzzle
Imagine you are working in a newly-accessible and under-explored area of an otherwise mature basin. Statistics show that on average 10% of structures are filled with gas; the rest are dry. Fortunately, you have some seismic analysis technology that allows you to predict the presence of gas with 80% reliability. In other words, four out of five gas-filled structures test positive with the technique, and when it is applied to water-filled structures, it gives a negative result four times out of five.
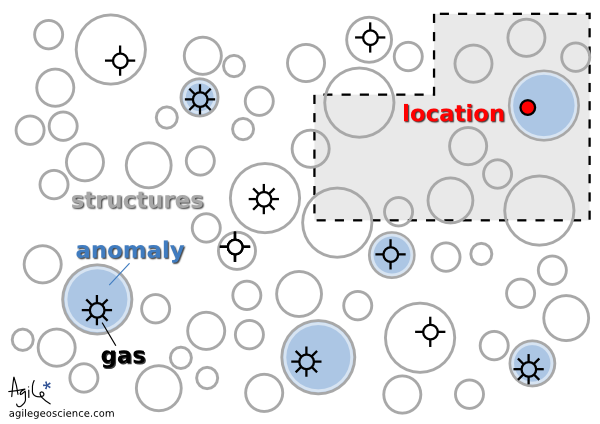
← It is thought that 10% of the structures in this play are gas-filled. Your seismic attribute test is thought to be 80% reliable, because four out of five times it has indicated gas correctly. You acquire the undrilled acreage shown by the grey polygon.
You acquire some undrilled acreage—the grey polygon— then delineate some structures and perform the analysis. One of the structures tests positive. If this is the only information you have, what is the probability that it is gas-filled?
This is a classic problem of embracing Bayesian likelihood and ignoring your built-in 'representativeness heuristic' (Kahneman et al, 1982, Judgment Under Uncertainty: Heuristics and Biases, Cambridge University Press). Bayesian probability combination does not come very naturally to most people but, once understood, can at least help you see the way to approach similar problems in the future. The way the problem is framed here, it is identical to the original formulation of Kahneman et al, the Taxicab Problem. This takes place in a town with 90 yellow cabs and 10 blue ones. A taxi is involved in a hit-and-run, witnessed by a passer-by. Eye witness reliability is shown to be 80%, so if the witness says the taxi was blue, what is the probability that the cab was indeed blue? Most people go with 80%, but in fact the witness is probably wrong. To see why, let's go back to the exploration problem and look at 100 test cases.
Break it down
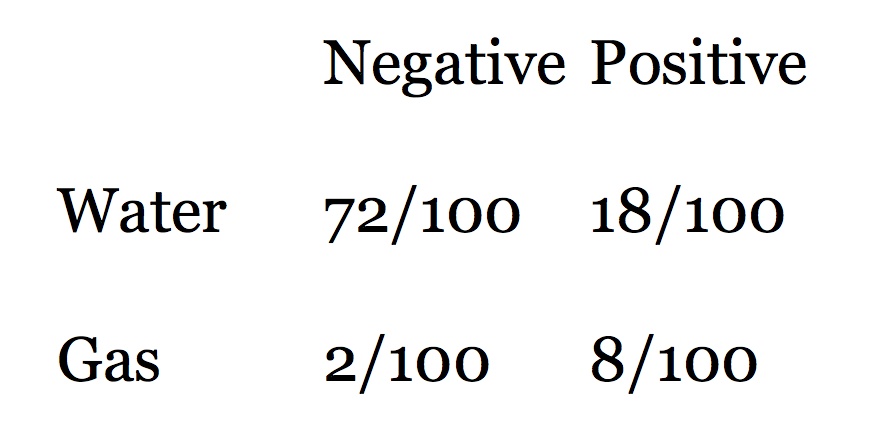 Looking at the rows in this table of outcomes, we see that there are 90 water cases and 10 gas cases. Eighty percent of the water cases test negative, and 80% of the gas cases test positive. The table shows that when we get a positive test, the probability that the test is true is not 0.80, but much less: 8/(8+18) = 0.31. In other words, a test that is mostly reliable is probably wrong when applied to an event that doesn't happen very often (a structure being gas charged). It's still good news for us, though, because a probability of discovery of 0.31 is much better than the 0.10 that we started with.
Looking at the rows in this table of outcomes, we see that there are 90 water cases and 10 gas cases. Eighty percent of the water cases test negative, and 80% of the gas cases test positive. The table shows that when we get a positive test, the probability that the test is true is not 0.80, but much less: 8/(8+18) = 0.31. In other words, a test that is mostly reliable is probably wrong when applied to an event that doesn't happen very often (a structure being gas charged). It's still good news for us, though, because a probability of discovery of 0.31 is much better than the 0.10 that we started with.
Here is Bayes' Theorem for calculating the probability P of event A (say, a gas discovery) given event B (say, a positive test in our seismic analysis):
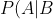 = \frac{P(B|A)\,P(A)}{P(B)} "P(A|B) = \frac{P(B|A)\,P(A)}{P(B)}")
So we can express our problem in these terms:
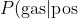 = \frac{0.8\times0.1}{0.8\times0.1 + 0.2\times0.9}=0.31 "P(\mathrm{gas}|\mathrm{pos}) = \frac{0.8\times0.1}{0.8\times0.1 + 0.2\times0.9}=0.31")
Are you sure about that?
This result is so counter-intuitive, for me at least, that I can't resist illustrating it with another well-known example that takes it to extremes. Imagine you test positive for a very rare disease, seismitis. The test is 99% reliable. But the disease affects only 1 person in 10 000. What is the probability that you do indeed have seismitis?
Notice that the unreliability (1%) of the test is much greater than the rate of occurrence of the disease (0.01%). This is a red flag. It's not hard to see that there will be many false positives: only 1 person in 10 000 are ill, and that person tests positive 99% of the time (almost always). The problem is that 1% of the 9 999 healthy people, 100 people, will test positive too. So for every 10 000 people tested, 101 test positive even though only 1 is ill. So the probability of being ill, given a positive test, is only about 1/101!
Lessons learned
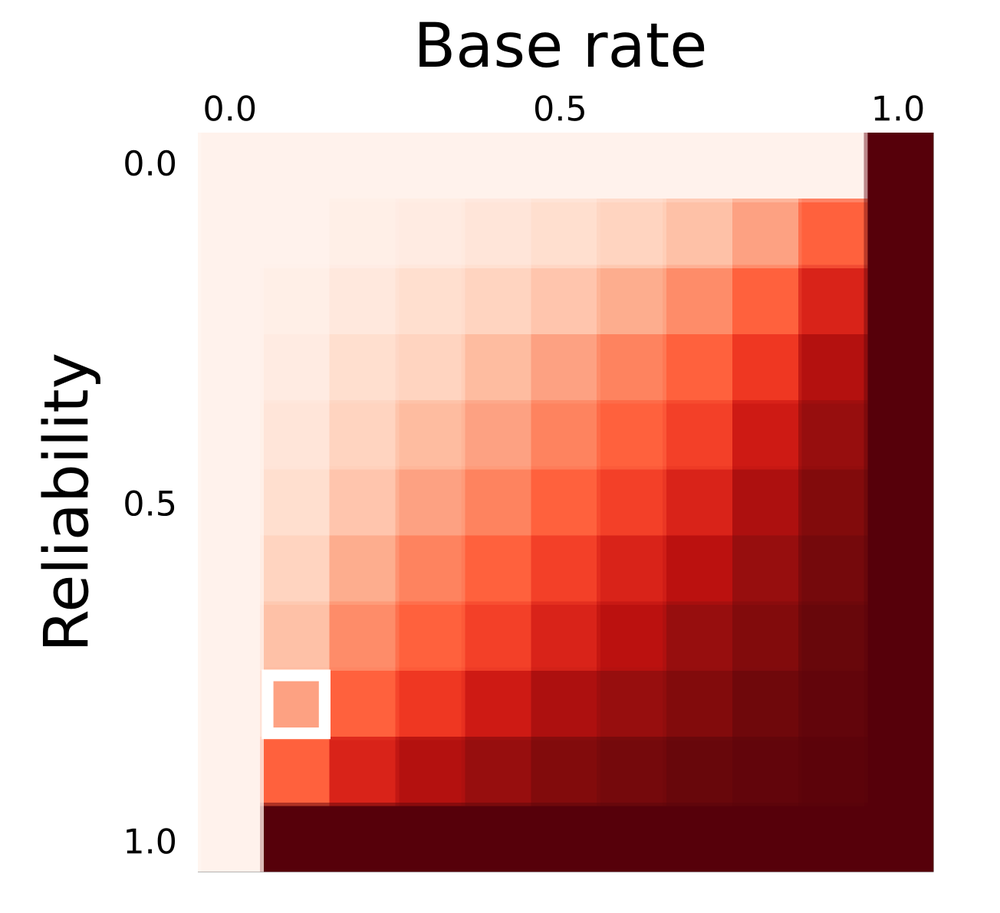 ← Predictive power (in Bayesian jargon, the posterior probability) as a function of test reliability and the base rate of occurrence (also called the prior probability of the event of phenomenon in question). The position of the scenario in the exploration problem is shown by the white square.
← Predictive power (in Bayesian jargon, the posterior probability) as a function of test reliability and the base rate of occurrence (also called the prior probability of the event of phenomenon in question). The position of the scenario in the exploration problem is shown by the white square.
Thanks to UBC Bioinformatics for the heatmap software, heatmap.notlong.com.

Next time you confidently predict something with a seismic attribute, stop to think not only about the reliability of the test you have made, but the rate of occurrence of the thing you're trying to predict. The heatmap shows how prediction power depends on both test reliability and the occurrence rate of the event. You may be doing worse (or better!) than you think.
Fortunately, in most real cases, there is a simple mitigation: use other, independent, methods of prediction. Mutually uncorrelated seismic attributes, well data, engineering test results, if applied diligently, can improve the odds of a correct prediction. But computing the posterior probability of event A given independent observations B, C, D, E, and F, is beyond the scope of this article (not to mention this author!).
This post is a version of part of my article The rational geoscientist, The Leading Edge, May 2010








 Except where noted, this content is licensed
Except where noted, this content is licensed