
All the wedges
/Wedges are a staple of the seismic interpreter’s diet. These simple little models show at a glance how two seismic reflections interact with each other when a rock layer thins down to — and below — the resolution limit of the data. We can also easily study how the interaction changes as we vary the wavelet’s properties, especially its frequency content.
Here’s how to make and plot a basic wedge model with Python in the latest version of bruges, v0.4.2:
import bruges as bg import matplotlib.pyplot as plt wedge, *_ = bg.models.wedge() plt.imshow(wedge)
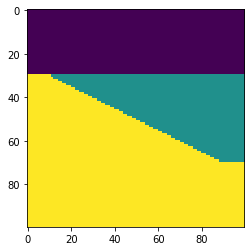
It really is that simple! This model is rather simplistic though: it contains no stratigraphy, and the numerical content of the 2D array is just a bunch of integers. Let’s instead make a P-wave velocity model, with an internal bed of faster rock inside the wedge:
strat = [2.35, (2.40, 2.50, 2.40), 2.65] wedge, *_ = bg.models.wedge(strat=strat) plt.imshow(wedge) plt.colorbar()

We can also choose to make the internal geometry top- or bottom-conformant, mimicking onlap or an unconformity, respectively.
strat = strat=[0, 7*[1,2], 3] wedge, *_ = bg.models.wedge(strat=strat, conformance='base' ) plt.imshow(wedge)

The killer feature of this new function might be using a log to make the stratigraphy, rather than just a few beds. This is straightforward to do with welly, because it makes selecting depth intervals and resampling a bit easier:
import welly gr = welly.Well.from_las('R-39.las').data['GR'] log_above = gr.to_basis(stop=2620, step=1.0) log_wedge = gr.to_basis(start=2620, stop=2720, step=1.0) log_below = gr.to_basis(start=2720, step=1.0) strat = (log_above, log_wedge, log_below) depth, width = (100, 400, 100), (40, 200, 40) wedge, top, base, ref = bg.models.wedge(depth=depth, width=width, strat=strat, thickness=(0, 1.5) ) plt.figure(figsize=(15, 6)) plt.imshow(wedge, aspect='auto') plt.axvline(ref, color='k', ls='--') plt.plot(top, 'r', lw=2) plt.plot(base, 'r', lw=2)

Notice that the function returns to you the top and base of the wedgy part, as well as the position of the ‘reference’, in this case the well.
I’m not sure if anyone wanted this feature… but you can make clinoform models too:
Lastly, the whole point of all this was to make a synthetic — the forward model of the seismic experiment. We can make a convolutional model with just a few more lines of code:
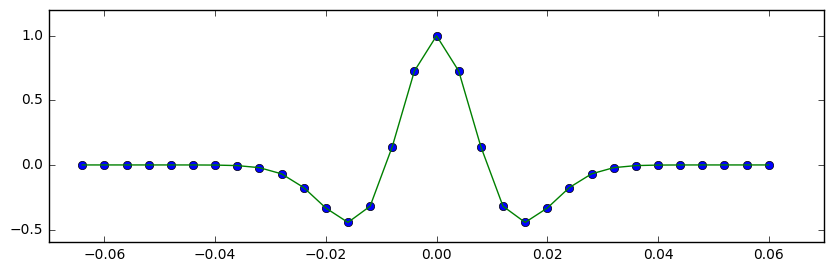
strat = np.array([2.32 * 2.65, # Layer 1 2.35 * 2.60, # Layer 2 2.35 * 2.62, # Layer 3 ]) # Fancy indexing into the rocks with the model. wedge, top, base, ref = bg.models.wedge(strat=strat) # Make reflectivity. rc = (wedge[1:] - wedge[:-1]) / (wedge[1:] + wedge[:-1]) # Get a wavelet. ricker = bg.filters.ricker(0.064, 0.001, 40) # Repeated 1D convolution for a synthetic. syn = np.apply_along_axis(np.convolve, arr=rc, axis=0, v=ricker, mode='same')

That covers most of what the tool can do — for now. I’m working on extending the models to three dimensions, so you will be able to vary layers or rock properties in the 3rd dimension. In the meantime, take these wedges for a spin and see what you can make! Do share your models on Twitter or LinkedIn, and have fun!









































 Except where noted, this content is licensed
Except where noted, this content is licensed {kind=link}