
Fear and loathing in oil & gas
/Sometimes you have to swallow your fear. This is one of those times.
The proliferation of 3D seismic in the 1980s was a major step forward for the petroleum industry. However, it took more than a decade for the 3D seismic method to become popular. During that decade, seismic equipment continued to evolve, particularly with the advent of telemetry recording systems that needed for doing 3D surveys offshore.
Things were never the same again. New businesses sprouted up to support it, and established service companies and tech companies exploded size and in order to keep up with the demand and all the new work.
Not so coincidently, another major shift happened in the late 1980s and early 1990s with the industry-wide shift to Sun workstations in order to cope with the crunching and rendering the overwhelming influx of all these digits. UNIX workstations with hilariously large cathode-ray tube monitors became commonplace. This industry helped make Sun and many other IT companies very wealthy, and once again everything was good. At least until Sun's picnic was trampled on by Linux workstations in the early 2000s, but that's another story...
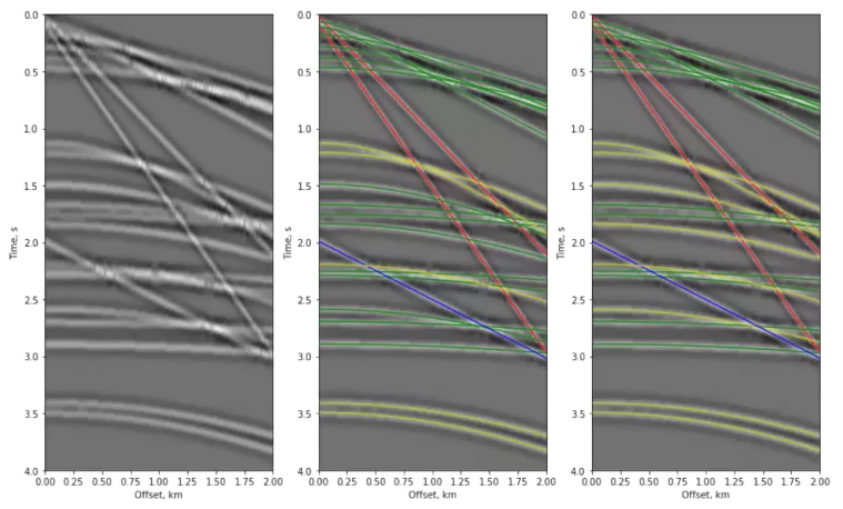
I think the advent of 3D seismic is one of many examples of the upstream oil and gas industry thriving on technological change. 3D seismic changed everything, facilitating progress in the full sense of the word and we never looked back. As an early career geoscientist, I don't know what the world was like before 3D seismic, but I have interpreted 2D data and I know it's an awful experience — even on a computer.
Debilitating skepticism?
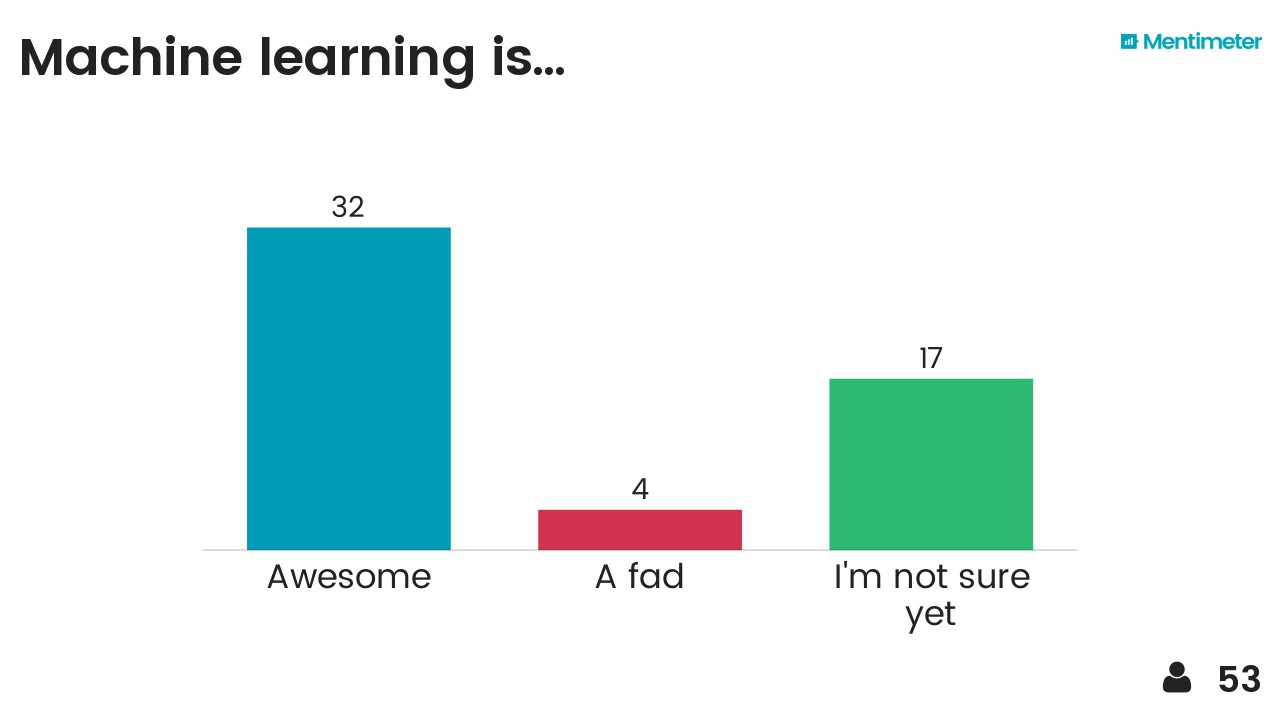
Today, in 2017, we find ourselves in the middle of the next major transformation. Like 3D seismic before it, machine learning will alter yesterday's landscape beyond all recognition. We've been through all of this before, but this time, for some reason it feels different. Many people are cautious, unconvinced about whether this next thing will live up to the hype. Other people are vibrating with excitement viewing the whole thing with rose-coloured glasses. Still others truly believe that it will fail — assertively rejecting hopes and over-excited claims that yes, artificial intelligence will catapult us into a better world, a world beyond our wildest dreams.
A little skepticism is healthy, but I meet a lot of people who are so skeptical about this next period of change that they are ignoring it. It feels to me like an unfair level of dismissal, a too-rigid stance. And it has left me rather perplexed: Why is there so much resistance and denial this time around? Why the apprehension?
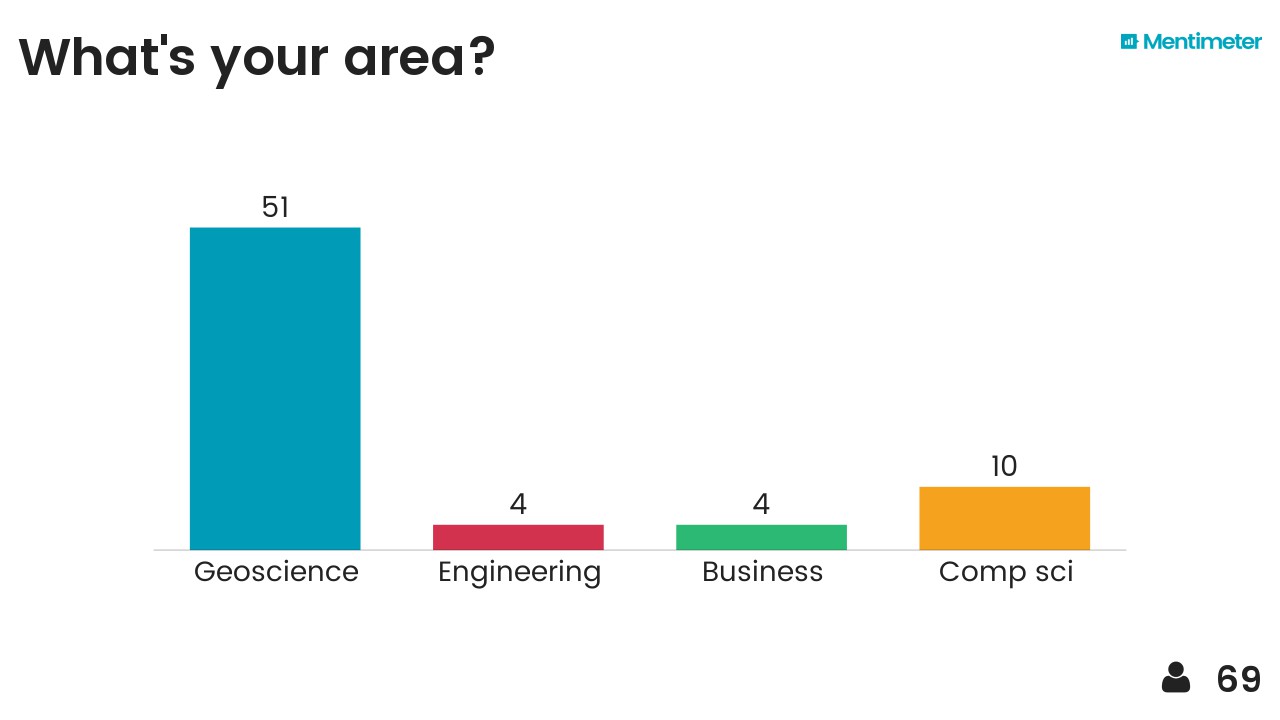
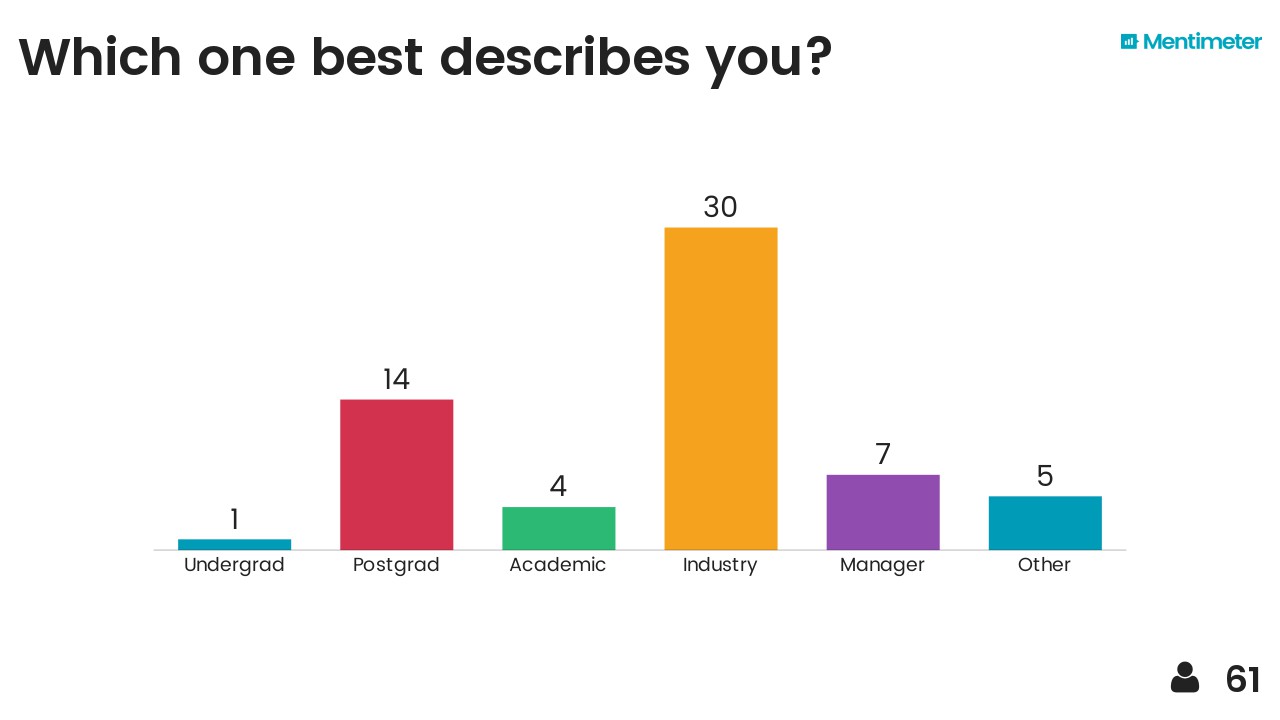
I'll wager the reason it is different this time because this change is happening to us, in spite of us, whether we like it or not. We're not in the driving seat. Most of us aren't even in the passenger seat. Unlike seismic technology and UNIX|Linux workstations, our sector has had little to do with this revolution. We haven't been pushing for it, instead, it is dragging us along with it. Worse, it's happening fast; even the people who are trying to keep up with it can barely hold on.
We need you
This is the opportunity of a lifetime. It's happening. High time to crank up the excitement, get involved, be a part of it. I for one want you to be part of it. Come along with us. We need you, whether you like it or not.
This post was provoked by a conversation on LinkedIn.



















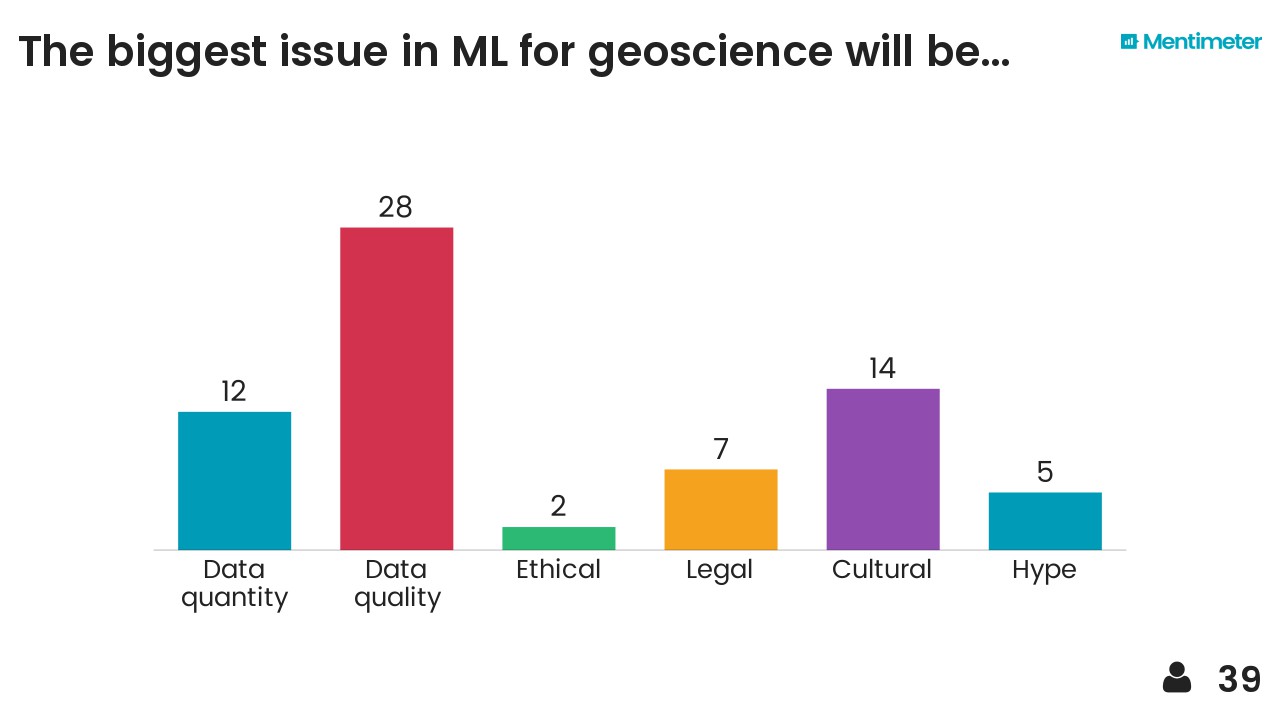
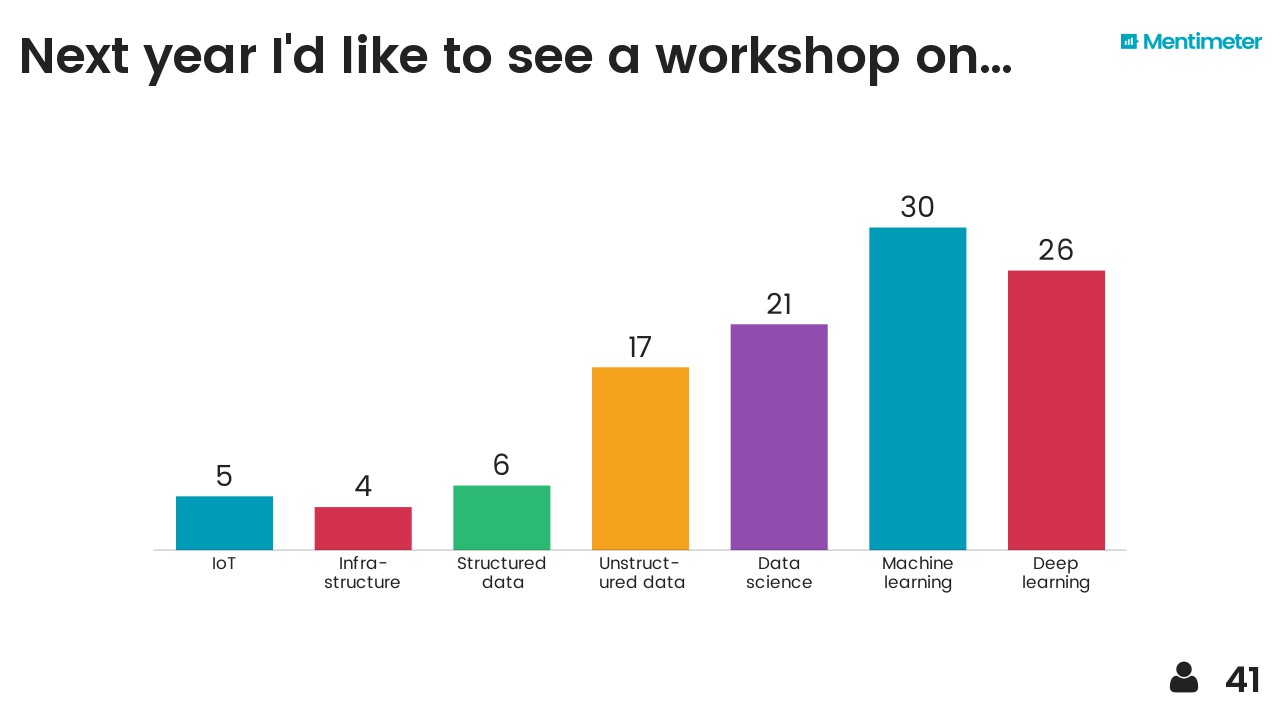
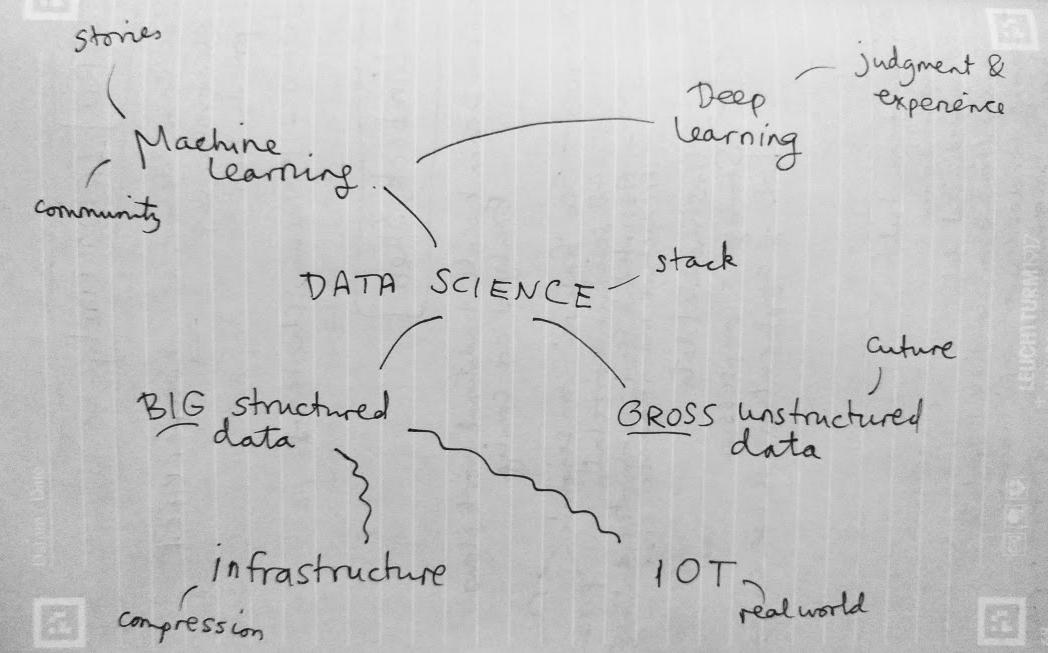































 Except where noted, this content is licensed
Except where noted, this content is licensed