
Which programming language should you learn first?
/The question I get asked most often is:
“I want to learn to code, where should I start?”
To which there’s really no perfect answer. It depends on a lot of things… Why do you want to learn to program? What domain are you in? Have you tried before? Do you like computers? Do your colleagues use anything in particular?
Undeterred by the futility, and inspired by an awesome blog post on freecodecamp.org, which advises you to learn JavaScript (not terrible advice), I thought I’d try to answer the question — for scientists. I adapted a rather old decision tree in that blog post to the specific needs of scientists. Here is the latest version:
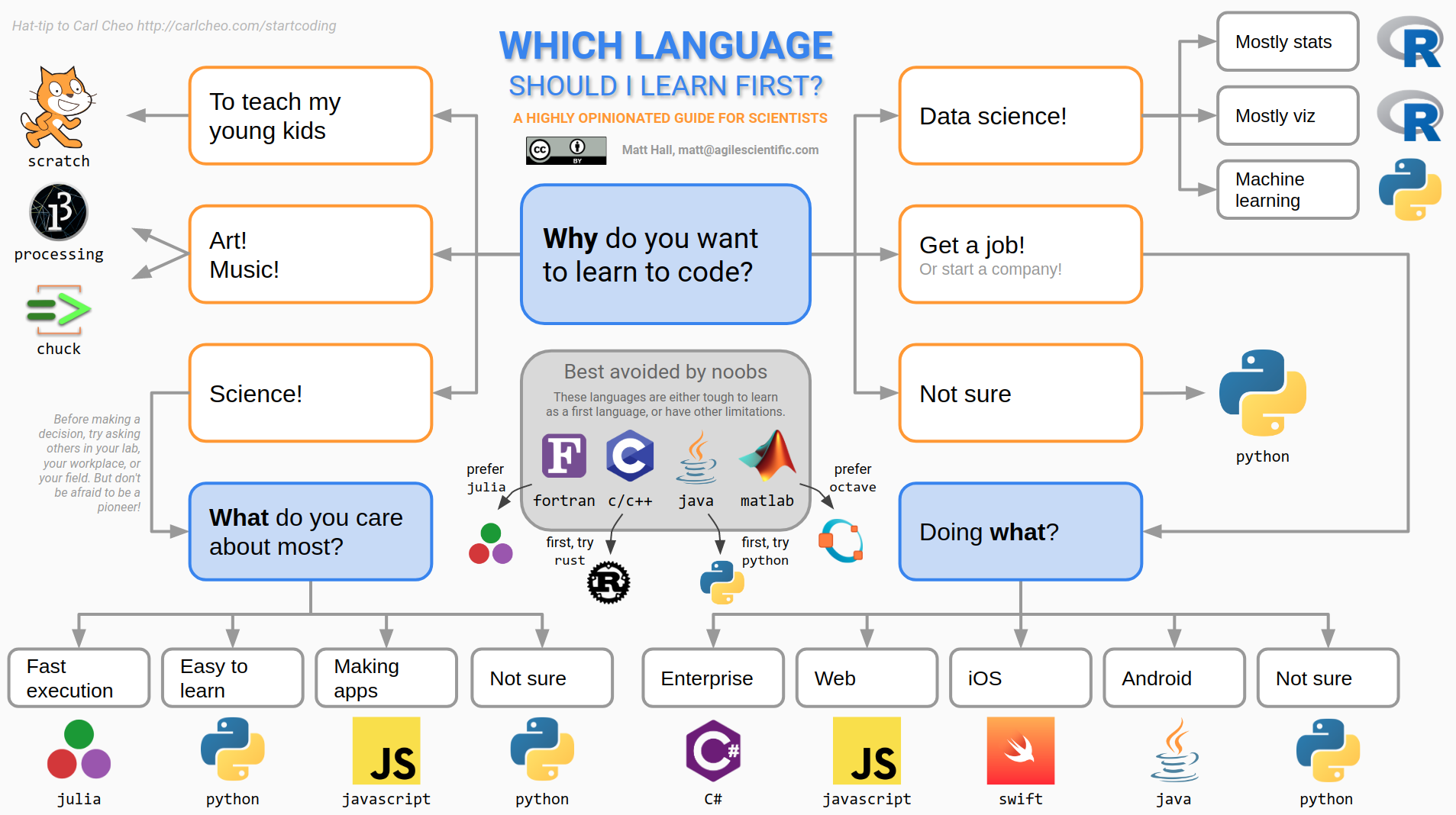
Yes, it does have a lot of Python on it. Yes, I am biased.
These sorts of things are necessarily rather one-dimensional. In an effort to give general advice, all the interesting corners are sanded down. For instance, there is definitely some domain specificity to languages. In the subsurface domain, a lot of geophysicists learned their craft in MATLAB, but today are excited about Julia. I think environmental folks are more into R. Geologists mostly still like coloured pencils best. And of course reservoir engineers mastered VBA years ago. Clearly, if you’re learning to code to start a postgraduate degree, you should probably find out what language others in your lab are using before you crack into that old copy of FORTRAN in a Weekend.*
Anyway, this decision tree thing provoked quite a bit of discussion on Software Underground and Twitter. Some people felt challenged, although my purpose was to suggest a starting point for people, not to say “Never touch Java” (although, seriously, never touch Java). It’s natural — learning to master a language takes years and people are sensitive to perceived criticism of how they spent their time. But this misses the point a bit — programming is really just about getting things done, preferably in an open language (<cough> not MATLAB). So what’s the quickest path for a new programmer to start getting things done?
I appreciated this thoughtful comment from Kris Kuhlman:
I think it worked out more or less that way for me. I learned a bit of BASIC as a 12-year-old, and knew enough assembly to crash a BBC Micro. Then I learned awk in 1993, and used it for basically everything — including many things it certainly was not designed for. I tried and failed to learn Java in 2002, instead picking up MATLAB… which led to Python in about 2008. I was a slow learner though; it took years to be convinced that I needed NumPy. (Yes, you can load seismic as a list of lists.)
In the end, you need several tools in your belt. Several people pointed out that SQL (a so-called ‘domain specific language’ rather than a full-blown programming language) is incredibly useful to know. I think you could say the same for HTML and maybe even XML — or perhaps JSON these days. Then again, maybe these stretch the definition of ‘programming language’ a bit too far. Besides, if you write code, you’ll meet them eventually.
In the end, the point is to get things done. Every language on that tree will enable you to get things done. (Admittedly, Scratch, Processing, ChucK have rather narrow domains.) Fortran has been around for 70 years (not a typo) and is still in the top 20 languages. So don’t sweat it — if Kris is right, you’ll need to learn 2 languages before one sticks anyway.
* There is no such book, lol.




























 Except where noted, this content is licensed
Except where noted, this content is licensed