
Smoothing, unsmoothness, and stuff
/
Day 2 at the SEG Annual Meeting in Las Vegas continued with 191 talks and dozens more posters. People are rushing around all over the place — there are absolutely no breaks, other than lunch, so it's easy to get frazzled. Here are my highlights:
Adam Halpert, Stanford
Image segmentation is an important class of problems in computer vision. An application to seismic data is to automatically pick a contiguous cloud of voxels from the 3D seismic image — a salt body, perhaps. Before trying to do this, it is common to reduce noise (e.g. roughness and jitter) by smoothing the image. The trick is to do this without blurring geologically important edges. Halpert did the hard work and assessed a number of smoothers for both efficacy and efficiency: median (easy), Kuwahara, maximum homogeneity median, Hale's bilateral [PDF], and AlBinHassan's filter. You can read all about his research in his paper online [PDF].
 Dave Hale, Colorado School of Mines
Dave Hale, Colorado School of Mines
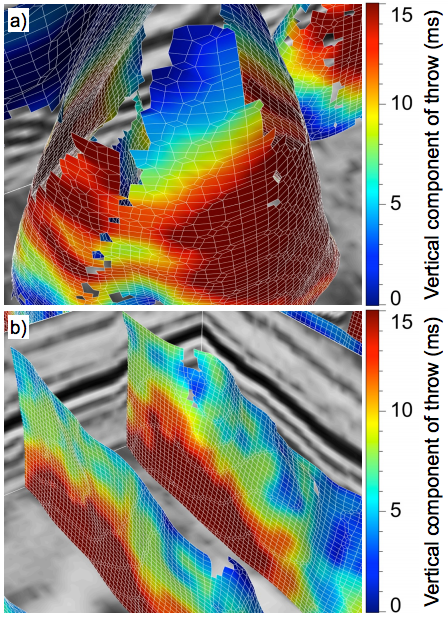
Automatic fault detection is a long-standing problem in interpretation. Methods tend to focus on optimizing a dissimilarity image of some kind (e.g. Bø 2012 and Dorn 2012), or on detecting planar discontinuities in that image. Hale's method is, I think, a new approach. And it seems to work well, finding fault planes and their throw (right).
Fear not, it's not complete automation — the method can't organize fault planes, interpret their meaning, or discriminate artifacts. But it is undoubtedly faster, more accurate, and more objective than a human. His test dataset is the F3 dataset from dGB's Open Seismic Repository. The shallow section, which resembles the famous polygonally faulted Eocene of the North Sea and elsewhere, contains point-up conical faults that no human would have picked. He is open to explanations of this geometry.
Other good bits
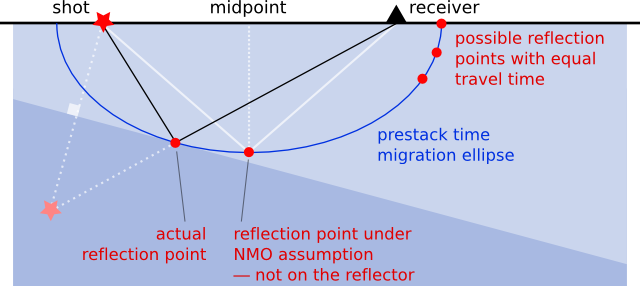
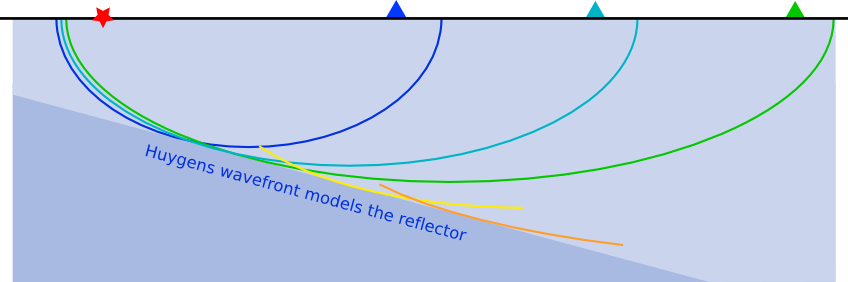
John Etgen and Chandan Kumar of BP made a very useful tutorial poster about the differences and similarities between pre-stack time and depth migration. They busted some myths about PreSTM:
- Time migration is actually not always more amplitude-friendly than depth migration.
- Time migration does not necessarily produce less noisy images.
- Time migration does not necessarily produce higher frequency images.
- Time migration is not necessarily less sensitive to velocity errors.
- Time migration images do not necessarily have time units.
- Time migrations can use the wave equation.
- But time migration is definitely less expensive than depth migration. That's not a myth.
Brian Frehner of Oklahoma State presented his research [PDF] to the Historical Preservation Committee, which I happened to be in this morning. Check out his interesting-looking book, Finding Oil: The Nature of Petroleum Geology.
Jon Claerbout of Stanford gave his first talk in several years. I missed it unfortunately, but Sergey Fomel said it was his highlight of the day, and that's good enough for me. Jon is a big proponent of openness in geophysics, so no surprise that he put his talk on YouTube days ago:
The image from Hale is copyright of SEG, from the 2012 Annual Meeting proceedings, and used here in accordance with their permissions guidelines. The DOI links in this post don't work at the time of writing — SEG is on it.
Dave Hale kindly pointed me to a video he made, highlighting those weird conical faults. I think it's wonderful that it's characters like Jon Claerbout and Dave Hale that are leading a new dimension to our technical conferences. Thanks Dave!













 Except where noted, this content is licensed
Except where noted, this content is licensed