
TRANSFORM happened!
/
How do you describe the indescribable?
Last week, Agile hosted the TRANSFORM unconference in Normandy, France. We were there to talk about the open suburface stack — the collection of open-source Python tools for earth scientists. We also spent time on the state of the Software Underground, a global community of practice for digital subsurface scientists and engineers. In effect, this was the first annual Software Underground conference. This was SwungCon 1.
The space
I knew the Château de Rosay was going to be nice. I hoped it was going to be very nice. But it wasn’t either of those things. It exceeded expectations by such a large margin, it seemed a little… indulgent, Excessive even. And yet it was cheaper than a Hilton, and you couldn’t imagine a more perfect place to think and talk about the future of open source geoscience, or a more productive environment in which to write code with new friends and colleagues.








It turns out that a 400-year-old château set in 8 acres of parkland in the heart of Normandy is a great place to create new things. I expect Gustave Flaubert and Guy de Maupassant thought the same when they stayed there 150 years ago. The forty-two bedrooms house exactly the right number of people for a purposeful scientific meeting.
This is frustrating, I’m not doing the place justice at all.
The work
This was most people’s first experience of an unconference. It was undeniably weird walking into a week-long meeting with no schedule of events. But, despite being inexpertly facilitated by me, the 26 participants enthusiastically collaborated to create the agenda on the first morning. With time, we appreciated the possibilities of the open space — it lets the group talk about exactly what it needs to talk about, exactly when it needs to talk about it.







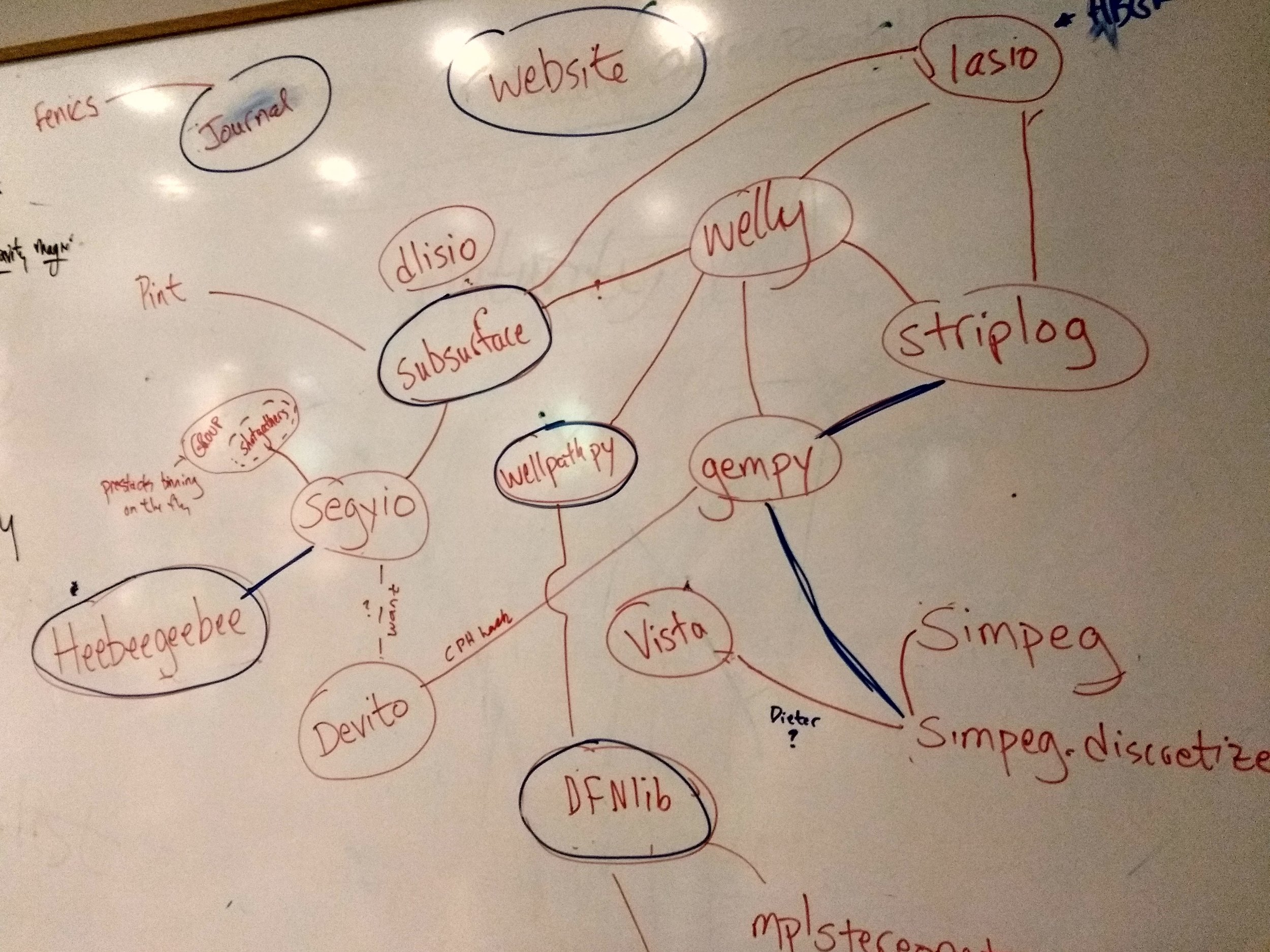
The topics ranged from the governance and future of the Software Underground, to the possibility of a new open access journal, interesting new events in the Software Underground calendar, new libraries for geoscience, a new ‘core’ library for wells and seismic, and — of course — machine learning. I’ll be writing more about all of these topics in the coming weeks, and there’s already lots of chatter about them on the Software Underground Slack (which hit 1500 members yesterday!).
The food
I can’t help it. I have to talk about the food.
…but I’m not sure where to start. The full potential of food — to satisfy, to delight, to start conversations, to impress, to inspire — was realized. The food was central to the experience, but somehow not even the most wonderful thing about the experience of eating at the chateau. Meals were prefaced by a presentation by the professionals in the kitchen. No dish was repeated… indeed, no seating arrangement was repeated. The cheese was — if you are into cheese — off the charts.
There was a professionalism and thoughtfulness to the dining that can perhaps only be found in France.










Sorry everyone. This was one of those occasions when you had to be there. If you weren’t there, you missed out. I wish you’d been there. You would have loved it.
The good news is that it will happen again. Stay tuned.




































 Except where noted, this content is licensed
Except where noted, this content is licensed