
All the time freaks
/ Thursday was our last day at the SEG Annual Meeting. Evan and I took in the Recent developments in time-frequency analysis workshop, organized by Mirko van der Baan, Sergey Fomel, and Jean-Baptiste Tary (Vienna). The workshop came out of an excellent paper I reviewed this summer, which was published online a couple of weeks ago:
Thursday was our last day at the SEG Annual Meeting. Evan and I took in the Recent developments in time-frequency analysis workshop, organized by Mirko van der Baan, Sergey Fomel, and Jean-Baptiste Tary (Vienna). The workshop came out of an excellent paper I reviewed this summer, which was published online a couple of weeks ago:
Tary, JB, RH Herrera, J Han, and M van der Baan (2014), Spectral estimation—What is new? What is next?, Rev. Geophys. 52. doi:10.1002/2014RG000461.
The paper compares the results of several time–frequency transforms on a suite of 'benchmark' signals. The idea of the workshop was to invite further investigation or other transforms. The organizers did a nice job of inviting contributors with diverse interests and backgrounds. The following people gave talks, several of them sharing their code (*):
- John Castagna (Lumina) with a review of the applications of spectral decomposition for seismic analysis.
- Steven Lin (NCU, Taiwan) on empirical methods and the Hilbert–Huang transform.
- Hau-Tieng Wu (Toronto) on the application of transforms to monitoring respiratory patterns in animals.*
- Marcílio Matos (SISMO) gave an entertaining, talk about various aspects of the problem.
- Haizhou Yang (Standford) on synchrosqueezing transforms applied to problems in anatomy.*
- Sergey Fomel (UT Austin) on Prony's method... and how things don't always work out.*
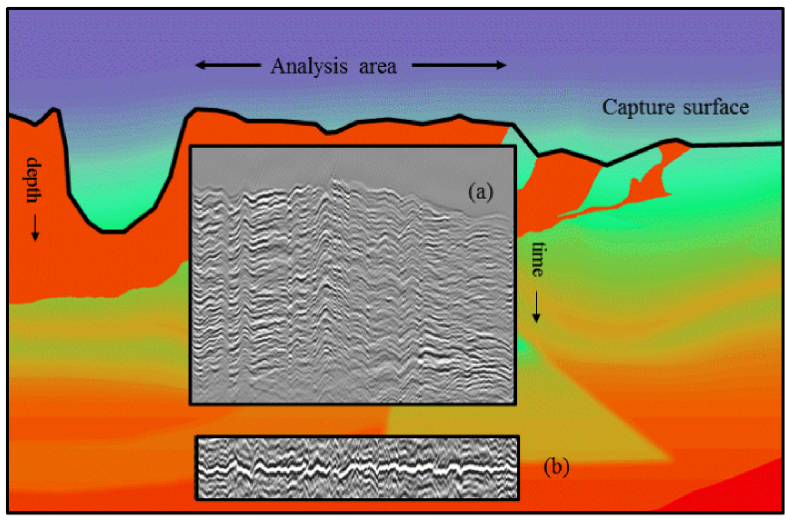
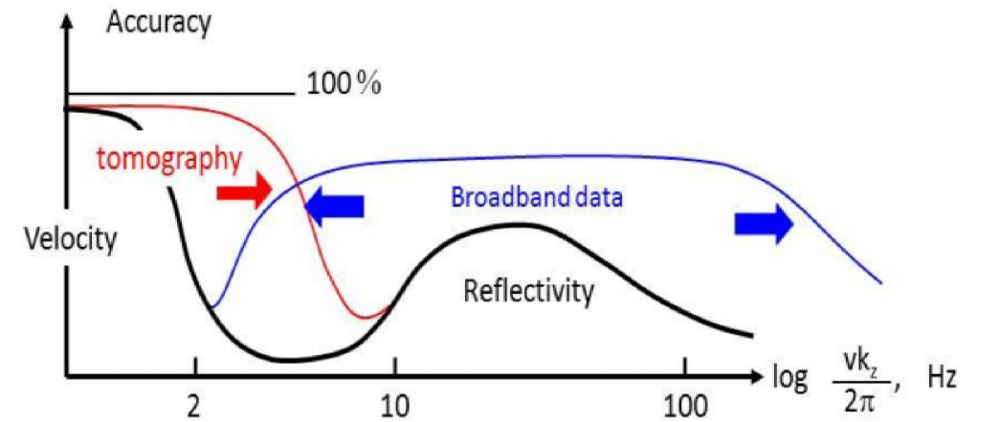
- Me, talking about the fidelity of time–frequency transforms, and some 'unsolved problems' (for me).*
- Mirko van der Baan (Alberta) on the results from the Tary et al. paper.
Some interesting discussion came up in the two or three unstructured parts of the session, organized as mini-panel discussions with groups of authors. Indeed, it felt like the session could have lasted longer, because I don't think we got very close to resolving anything. Some of the points I took away from the discussion:
- My observation: there is no existing survey of the performance of spectral decomposition (or AVO) — these would be great risking tools.
- Castagna's assertion: there is no model that predicts the low-frequency 'shadow' effect (confusingly it's a bright thing, not a shadow).
- There is no agreement on whether the so-called 'Gabor limit' of time–frequency localization is a lower-bound on spectral decomposition. I will write more about this in the coming weeks.
- Should we even be attempting to use reassignment, or other 'sharpening' tools, on broadband signals? To put it another way: does instantaneous frequency mean anything in seismic signals?
- What statistical measures might help us understand the amount of reassignment, or the precision of time–frequency decompositions in general?
The fidelity of time–frequency transforms
My own talk was one of the hardest I've ever done, mainly because I don't think about these problems very often. I'm not much of a mathematician, so when I do think about them, I tend to have more questions than insights, so I made my talk into a series of questions for the audience. I'm not sure I got much closer to any answers, but I have a better idea of my questions now... which is a kind of progress I suppose.
Here's my talk (latest slides — GitHub repo). Comments and feedback are, as always, welcome.






















 Except where noted, this content is licensed
Except where noted, this content is licensed