
Productive chaos
/Wednesday was a good day.

Over 150 participants came to Room 251 for all or part of the first 'unsession' at the AAPG Annual Conference and Exhibition in Salt Lake City. I was one of the hosts of the event, and emceed the afternoon.
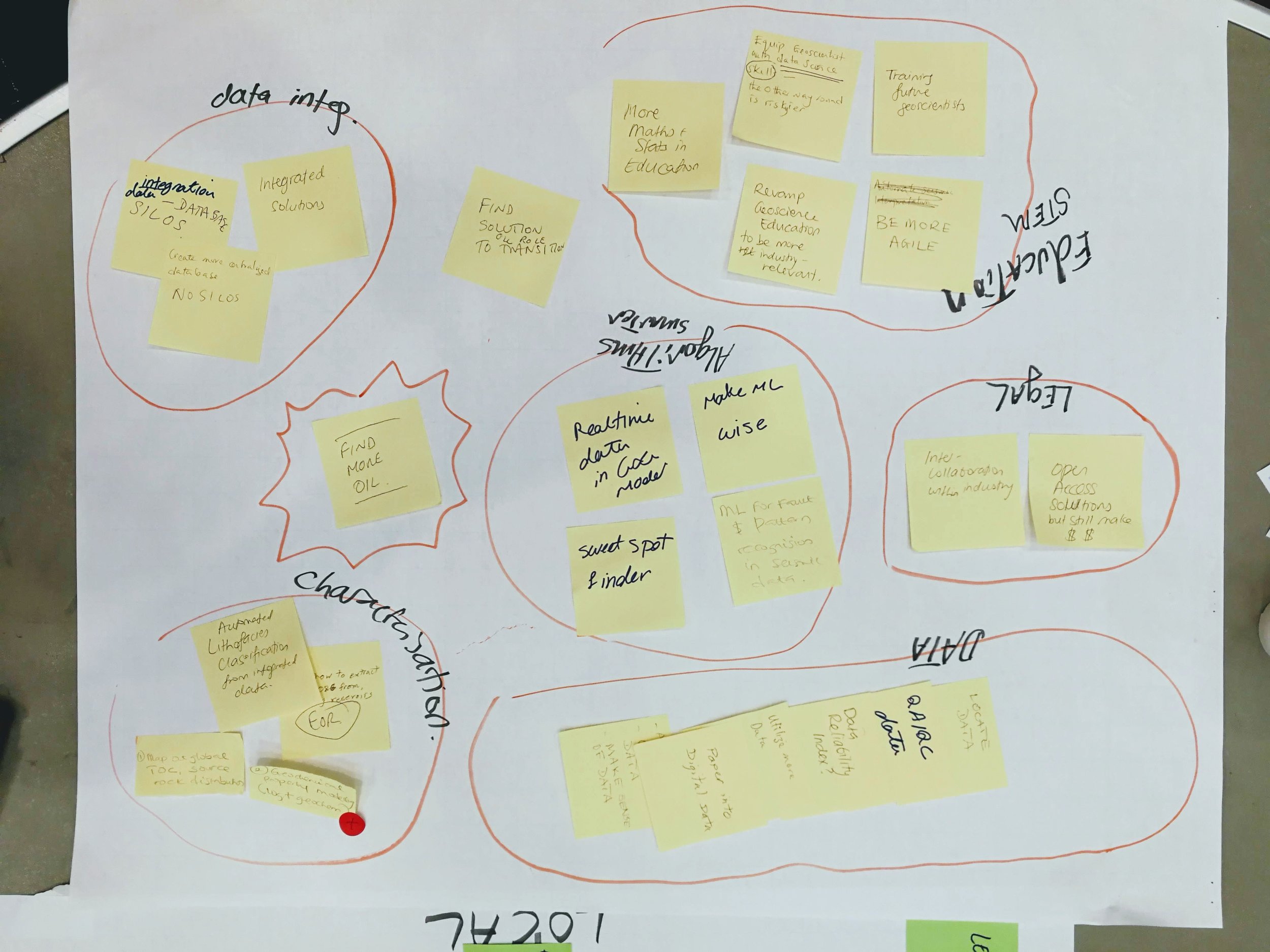
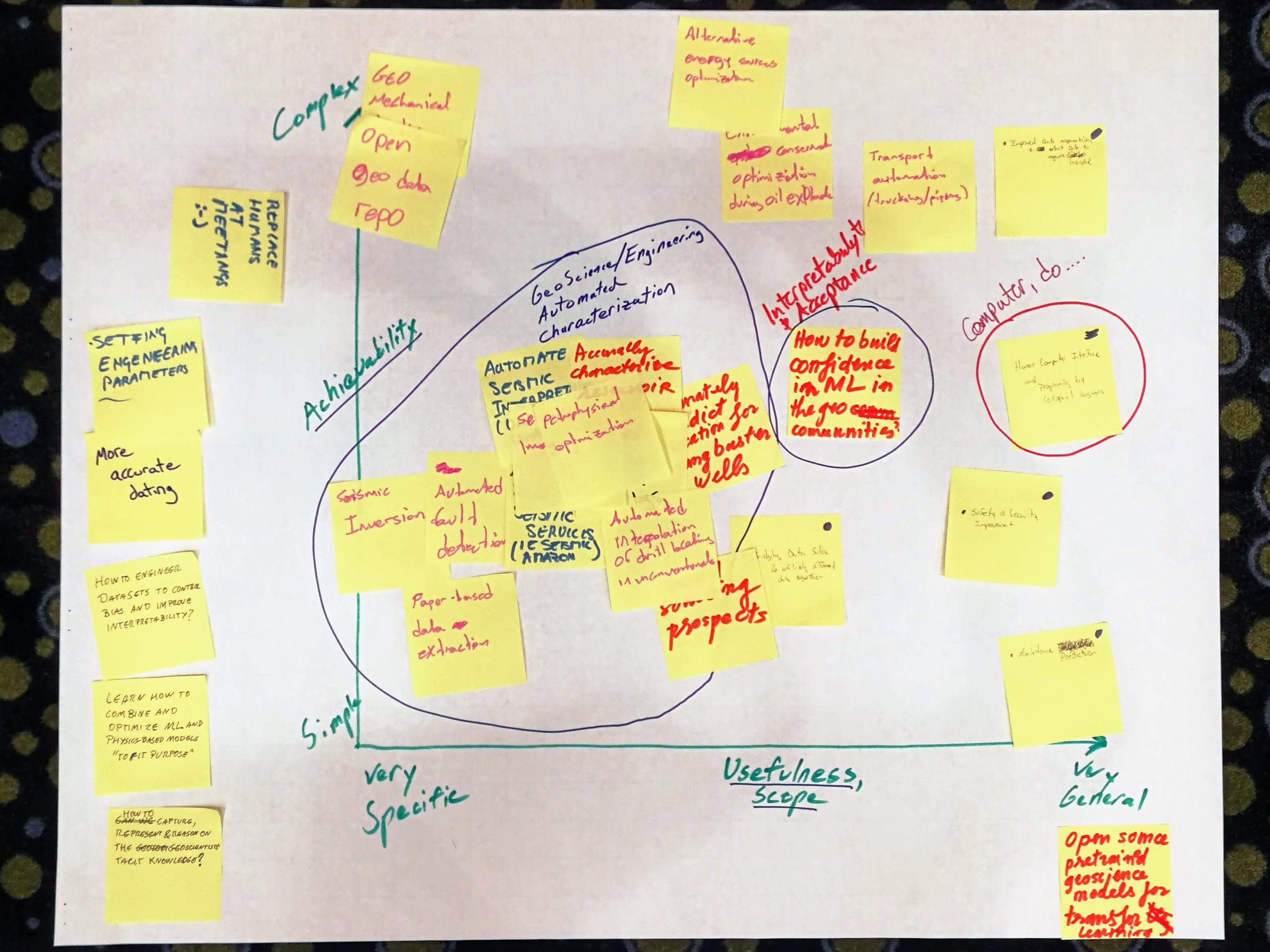
In a nutshell, it was awesome. I have facilitated unsessions before, but this event was on a new scale. Twelve tables of 8–10 seats — covered in sticky notes, stickers, coloured pens, and large sheets of paper — quickly filled up. Together, we burned about 10 person-weeks of human productivity, raising the temperature in the room by several degrees in the process.
Diversity means good conversation
On the way in, people self-identified as mostly software (blue name tags) or mostly soft rocks (red), as a non-serious way to get a handle on how many data scientists we had vs how many people are focused on the rocks themselves — without, I hope, any kind of value judgment. The ratio was about 1:2.
As people continued to drift in, we counted people identifying with various categories, to get a very rough idea of who was in the room. The results are shown here. In addition, I counted 24 women present at the start. Part of the point here is to introduce participants to each other, but there's another purpose too. AAPG, like many scientific organizations, is grappling with diversity today. Like others, it needs to do much better. A small part of the solution is, I think, to name it and measure how we're doing at every opportunity. It's one way to pay more attention.
Harder to capture is the profound level of job diversity. People responsible for billion-dollar budgets sat with graduate students, AAPG medal winners with SEC executives. We even had a venture capitalist and a physician.
Look at all these lovely people:








Tangible and intangible output
At the start of the session, I told the room I wanted to fill the walls with things we made — with data. We easily achieved this, producing a survey of the skills geoscientists will need in the future, hundreds of high-value machine learning tasks in geoscience, a ranked list of the most interesting of these, and even some problem analysis of some of them. None of this was definitive, but I hope it will provide grist for the mill of future conversations about machine learning in geoscience.
As well as these tangible products, each person in the room walked away with new connections and new ideas — about machine learning, about collaboration, and about what scientific meetings can be like.





Acknowledgments
A lot of people contributed to making this event happen.
My unsession co-chairs, Brendon Hall and Yan Zaretskiy of Enthought — spent several hours on the phone with me over the last few weeks, shaping the content and flow of an event that was a bit, er, fuzzy.
We seeded the tables with some of the Software Underground crowd who were in town for the hackathon and AAPG. This ensures that there's no failure case: twelve people are definitely coming. And in the unlikely event that 100 people come, there are twelve allies to manage some of the chaos. Heartfelt thanks to the table hosts:
- Didi Ooi of the University of Bristol
- Graham Ganssle of Expero
- Lisa Stright of Colorado State University
- Thomas Martin of Colorado School of Mines
- Tom Creech of ExxonMobil
- David Holmes of Dell EMC
- Steve Purves of Euclidity
- Diego Castaneda of Agile
- Evan Bianco of Agile
Jenny Cole of SEG came along to observe the session and I appreciated her enthusiastic help as it became clear we were in for more than the usual amount of entropy in the room. Theresa Curry of AAPG did an amazing job getting the venue set up, providing refreshments, and ensuring the photographers were there to capture some of the action. The ACE 2018 organizing committee, especially Zane Jobe and Lauren Birgenheier, did their part by agreeing to supprt including such a weird-sounding thing in the program.
Finally, thank you to the 100+ scientists that came to the event, not knowing at all what to expect. It was a privilege to receive your enthusiastic participation and thoughtful contributions. Let's do it again some time!
We will digitize the ideas and products of the unsession over the coming weeks. They will be released under an open license. Watch this space for updates.
If you're interested in the methodology we use for these events, check out Proceedings of an unsession in CSEG Recorder, November 2013. If you'd like help running an event like this, get in touch.















































































 Except where noted, this content is licensed
Except where noted, this content is licensed