
Big open data... or is it?
/Huge news for data scientists and educators. Equinor, the company formerly known as Statoil, has taken a bold step into the open data arena. On Thursday last week, it 'disclosed' all of its subsurface and production data for the Volve oil field, located in the North Sea.
What's in the data package?
A lot! The 40,000-file package contains 5TB of data, that's 5,000GB!
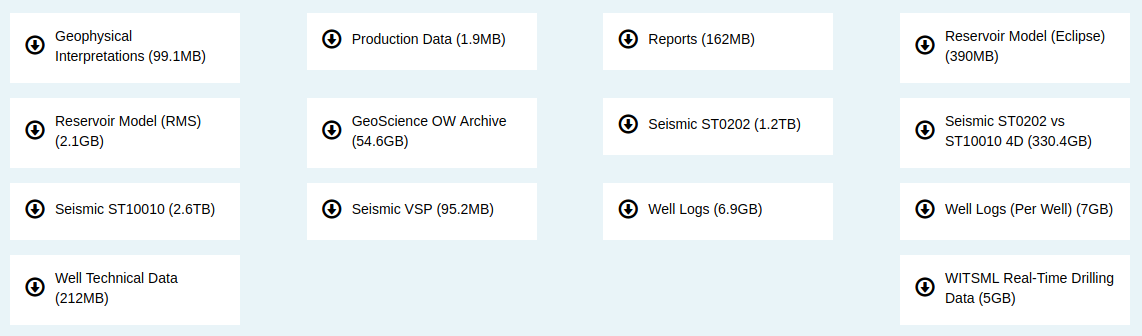
This collection is substantially larger, both deeper and broader, than any other open subsurface dataset I know of. Most excitingly, Equinor has released a broad range of data types, from reports to reservoir models: 3D and 4D seismic, well logs and real-time drilling records, and everything in between. The only slight problem is that the seismic data are bundled in very large files at the moment; we've asked for them to be split up.
Questions about usage rights

Regular readers of this blog will know that I like open data. One of the cornerstones of open data is access, and there's no doubt that Equinor have done something incredible here. It would be preferable not to have to register at all, but free access to this dataset — which I'm guessing cost more than USD500 million to acquire — is an absolutely amazing gift to the subsurface community.
Another cornerstone is the right to use the data for any purpose. This involves the owner granting certain privileges, such as the right to redistribute the data (say, for a class exercise) or to share derived products (say, in a paper). I'm almost certain that Equinor intends the data to be used this way, but I can't find anything actually granting those rights. Unfortunately, if they aren't explicitly granted, the only safe assumption is that you cannot share or adapt the data.
For reference, here's the language in the CC-BY 4.0 licence:
Subject to the terms and conditions of this Public License, the Licensor hereby grants You a worldwide, royalty-free, non-sublicensable, non-exclusive, irrevocable license to exercise the Licensed Rights in the Licensed Material to:
- reproduce and Share the Licensed Material, in whole or in part; and
- produce, reproduce, and Share Adapted Material.
You can dig further into the requirements for open data in the Open Data Handbook.
The last thing we need is yet another industry dataset with unclear terms, so I hope Equinor attaches a clear licence to this dataset soon. Or, better still, just uses a well-known licence such as CC-BY (this is what I'd recommend). This will clear up the matter and we can get on with making the most of this amazing resource.
More about Volve
The Volve field was discovered in 1993, but not developed until 15 years later. It produced oil and gas for 8.5 years, starting on 12 February 2008 and ending on 17 September 2016, though about half of that came in the first 2 years (see below). The facility was the Maersk Inspirer jack-up rig, standing in 80 m of water, with an oil storage vessel in attendance. Gas was piped to Sleipner A. In all, the field produced 10 million Sm³ (63 million barrels) of oil, so is small by most standards, with a peak rate of 56,000 barrels per day.

Volve production over time in standard m³ (i.e. at 20°C). Multiply by 6.29 for barrels.
The production was from the Jurassic Hugin Formation, a shallow-marine sandstone with good reservoir properties, at a depth of about 3000 m. The top reservoir depth map from the discovery report in the data package is shown here. (I joined Statoil in 1997, not long after this report was written, and the sight of this page brings back a lot of memories.)
The top reservoir depth map from the discovery report. The Volve field (my label) is the small closure directly north of Sleipner East, with 15/9-19 well on it.
Get the data
To explore the dataset, you must register in the 'data village', which Equinor has committed to maintaining for 2 years. It only takes a moment. You can get to it through this link.
Let us know in the comments what you think of this move, and do share what you get up to with the data!







































 Except where noted, this content is licensed
Except where noted, this content is licensed