
The machine learning algo zoo
/One of the wonderful, but also baffling, things about machine learning is that there are so many ways to do it. At some very high level, most of them do something like this (highlighting some jargon):
The human settles on a task (“Predict lithology”) and finds a bunch of data relevant to that task (say, some well logs A, B, and C). Then the human has to come up with some known instances or examples where these well log data go with those lithology labels.
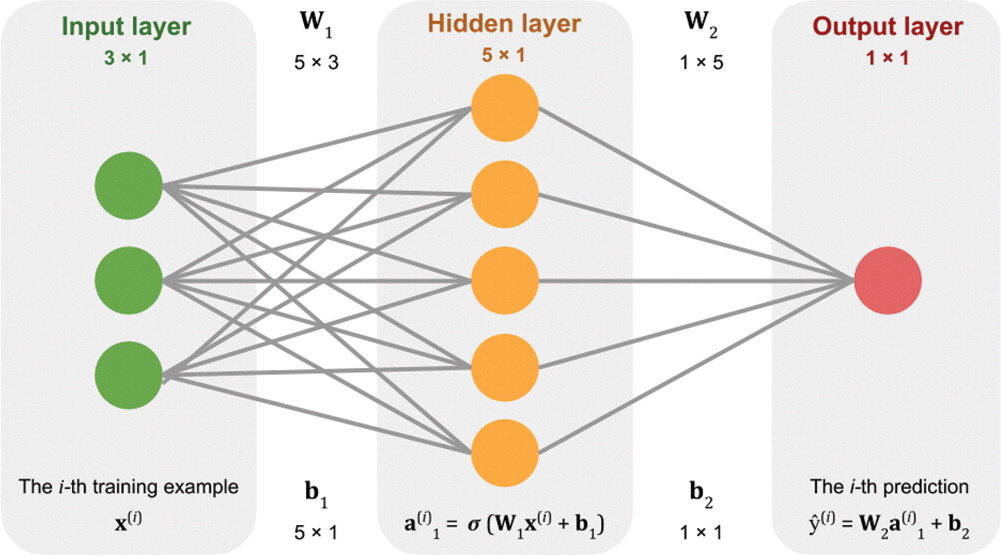
Stuff the logs into an equation. Not an equation like A + B + C, because there’s nothing to tweak in that equation. The equation needs parameters or coefficients, like \(\alpha A + \beta B + \gamma C\). The machine can tweak those Greek letters to change the output. At first, they’ll be random guesses.
See how the output of that equation, which is the machine’s prediction, compares to the known labels. Come up with another equation whose output is a good measure of how far away the predictions are from the known labels. This distance is called the cost, and the equation to compute it the cost function.
Now that the machine has something to guess (the Greek parameters) and a way to know how well its doing (the cost function), it just needs a way to minimize the cost, or to put it another way, optimize the parameters. This optimization process is called learning.
Together, these steps constitute a learning algorithm. An algorithm with a set of optimized weights is usually referred to simply as a model.
All the algorithms
Every piece of this story is worth a whole blog post on its own, but for today let’s stay high-level.
The problem is that the algorithm zoo can be overwhelming. My post last week was an attempt to compare a lot of regression algorithms, in terms of how they make sense of three synthetic datasets.
Today I’m sharing a Big Giant Spreadsheet™ that attempts to compare some of the most popular ‘shallow’ learning algorithms in terms of their most important characteristics. For example, can they predict probabilities? Are they deterministic? What are the key hyperparameters? And so on.
Here’s a small version of the table (see the links below for other versions):
There’s a PDF version here — and here’s the original spreadsheet.
Eventually, I’m visualizing a poster for the wall. I think it would be nice to have some equations on here. Maybe the plots from the various comparisons too (see last weeks post!). And even more advice, like which ones break when you have too many features. What else would you like to see on there?
































 Except where noted, this content is licensed
Except where noted, this content is licensed