
Dynamic geology at AAPG
/ Brad Moorman stands next to his 48 inch (122 cm) Omni Globe spherical projection system on the AAPG exhibition floor, greeting passers by drawn in by its cycling animations of Getech's dynamic plate reconstructions. His map-lamp projects evolutionary visions of geologic processes like a beacon of inspiration for petroleum explorers.
Brad Moorman stands next to his 48 inch (122 cm) Omni Globe spherical projection system on the AAPG exhibition floor, greeting passers by drawn in by its cycling animations of Getech's dynamic plate reconstructions. His map-lamp projects evolutionary visions of geologic processes like a beacon of inspiration for petroleum explorers.
I've attended several themed sessions over the first day and a half at AAPG and the ones that have stood out for me have had this same appeal.
Computational stratigraphy
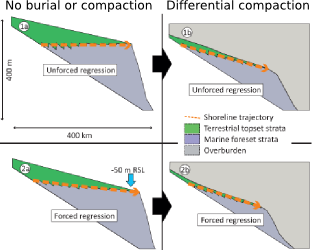 Processes such as accommodation rate and sedimentation rate can be difficult to unpeel from stratal geometries. Guy Prince's PhD Impact of non-uniqueness on sequence stratigraphy used a variety of input parameters and did numerical computations to make key stratigraphic surfaces with striking similarity. By forward modeling the depositional dynamics, he showed that there are at least two ways to make a maximum flooding surface, a sequence boundary, and top set aggradations. Non-uniqueness implies that there isn't just one model that fits the data, nor two, however Guy cleverly made simple comparisons to illustrate such ambiguities. The next step in this methodology, and it is a big step, is to express the entire model space: just how many solutions are there?
Processes such as accommodation rate and sedimentation rate can be difficult to unpeel from stratal geometries. Guy Prince's PhD Impact of non-uniqueness on sequence stratigraphy used a variety of input parameters and did numerical computations to make key stratigraphic surfaces with striking similarity. By forward modeling the depositional dynamics, he showed that there are at least two ways to make a maximum flooding surface, a sequence boundary, and top set aggradations. Non-uniqueness implies that there isn't just one model that fits the data, nor two, however Guy cleverly made simple comparisons to illustrate such ambiguities. The next step in this methodology, and it is a big step, is to express the entire model space: just how many solutions are there?
If you were a farmer here, you lost your land
Henry Posamentier, seismic geomorphologist at Chevron, showed extremely high-resolution 3D sparker seismic imaging just beneath the seafloor in the Gulf of Thailand. Because this locale is more than 1000 km from the nearest continental shelf, it has been essentially unaffected by sea-level change, making it an ideal place to study pure fluvial depositional patterns. Such fluvial systems result in reservoirs in their accretionary point bars, but they are hard to predict.
 To make his point, Henry showed a satellite image of the Ping River from a few years ago in the north of Chiang Mai, where meander loops had shifted sporadically in response to one flood season: "If you were a farmer here, you lost your land."
To make his point, Henry showed a satellite image of the Ping River from a few years ago in the north of Chiang Mai, where meander loops had shifted sporadically in response to one flood season: "If you were a farmer here, you lost your land."
Wells can tell about channel thickness, and seismic may resolve the channel width and the sinuosity, but only a dynamic model of the environment can suggest how well-connected is the sand.
The evolution of a single meandering channel belt
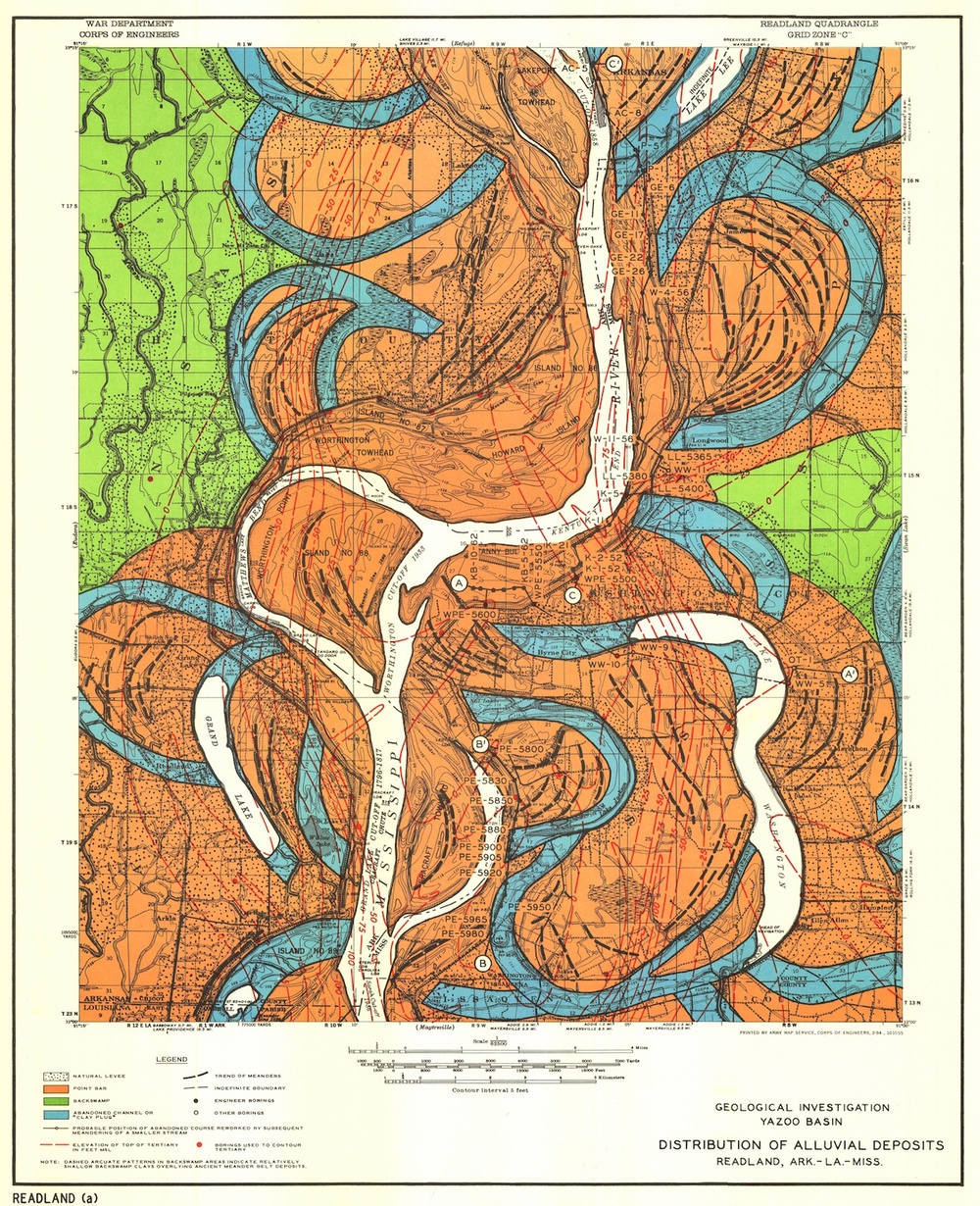 Ron Boyd from ConocoPhillips showed a four-step process investigating the evolution of a single channel belt in his talk, Tidal-Fluvial Sedimentology and Stratigraphy of the McMurray Formation.
Ron Boyd from ConocoPhillips showed a four-step process investigating the evolution of a single channel belt in his talk, Tidal-Fluvial Sedimentology and Stratigraphy of the McMurray Formation.
- Start with a cartoon facies interpretation of channel evolution.
- Trace out the static geomorphological model on seismic time slices.
- Identify directions of fluvial migrations point by point, time step by time step.
- Distribute petrophysical properties within each channel element in chronological sequence.
Mapping the dynamics of a geologic scenario along a timeline gives you access to all the pieces of a single geologic puzzle. But what really matters is how that puzzle compares with the handful of pieces in your hand.
More tomorrow — stay tuned.
Google Earth imagery ©2014 DigitalGlobe, maps ©2014 Google
This post was modified on April 16, 2014, mentioning and giving redirects to Getech.












 Except where noted, this content is licensed
Except where noted, this content is licensed