 This interview is part of a series of conversations between Satinder Chopra and the authors of the book 52 Things You Should Know About Geophysics (Agile Libre, 2012). The first three appeared in the October 2013 issue of the CSEG Recorder, the Canadian applied geophysics magazine, which graciously agreed to publish them under a CC-BY license.
This interview is part of a series of conversations between Satinder Chopra and the authors of the book 52 Things You Should Know About Geophysics (Agile Libre, 2012). The first three appeared in the October 2013 issue of the CSEG Recorder, the Canadian applied geophysics magazine, which graciously agreed to publish them under a CC-BY license.
Satinder Chopra: Seismic data contain massive amounts of information, which has to be extracted using the right tools and knowhow, a task usually entrusted to the seismic interpreter. This would entail isolating the anomalous patterns on the wiggles and understanding the implied subsurface properties, etc. What do you think are the challenges for a seismic interpreter?
Evan Bianco: The challenge is to not lose anything in the abstraction.
The notion that we take terabytes of prestack data, migrate it into gigabyte-sized cubes, and reduce that further to digitized surfaces that are hundreds of kilobytes in size, sounds like a dangerous discarding of information. That's at least 6 orders of magnitude! The challenge for the interpreter, then, is to be darn sure that this is all you need out of your data, and if it isn't (and it probably isn't), knowing how to go back for more.
SC: How do you think some these challenges can be addressed?
EB: I have a big vision and a small vision. Both have to do with documentation and record keeping. If you imagine the entire seismic experiment upon a sort of conceptual mixing board, instead of as a linear sequence of steps, elements could be revisited and modified at any time. In theory nothing would be lost in translation. The connections between inputs and outputs could be maintained, even studied, all in place. In that view, the configuration of the mixing board itself becomes a comprehensive and complete history for the data — what's been done to it, and what has been extracted from it.
The smaller vision: there are plenty of data management solutions for geospatial information, but broadcasting the context that we bring to bear is a whole other challenge. Any tool that allows people to preserve the link between data and model should be used to transfer the implicit along with the explicit. Take auto-tracking a horizon as an example. It would be valuable if an interpreter could embed some context into an object while digitizing. Something that could later inform the geocellular modeler to proceed with caution or certainty.
SC: One of the important tasks that a seismic interpreter faces is the prediction about the location of the hydrocarbons in the subsurface. Having come up with a hypothesis, how do you think this can be made more convincing and presented to fellow colleagues?
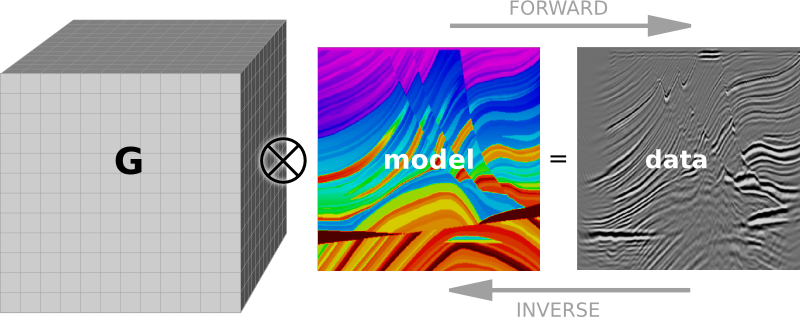
EB: Coming up with a hypothesis (that is, a model) is solving an inverse problem. So there is a lot of convincing power in completing the loop. If all you have done is the inverse problem, know that you could go further. There are a lot of service companies who are in the business of solving inverse problems, not so many completing the loop with the forward problem. It's the only way to test hypotheses without a drill bit, and gives a better handle on methodological and technological limitations.
SC: You mention "absolving us of responsibility" in your article. Could you elaborate on this a little more? Do you think there is accountability of sorts practiced in our industry?
EB: I see accountability from a data-centric perspective. For example, think of all the ways that a digitized fault plane can be used. It could become a polygon cutting through a surface on map. It could be a wall within a geocellular model. It could be a node in a drilling prognosis. Now, if the fault is mis-picked by even one bin, this could show up hundreds of metres away, depending on the dip of the fault, compared to the prognosis. Practically speaking, accounting for mismatches like this is hard, and is usually done in an ad hoc way, if at all. What caused the error? Was it the migration or was it the picking? Or what about the error in the measurement of the drill-bit? I think accountability is loosely practised at best because we don't know how to reconcile all these competing errors.
Until data can have a memory, being accountable means being diligent with documentation. But it is time-consuming, and there aren’t as many standards as there are data formats.
SC: Declaring your work to be in progress could allow you to embrace iteration. I like that. However, there is usually a finite time to complete a given interpretation task; but as more and more wells are drilled, the interpretation could be updated. Do you think this practice would suit small companies that need to ensure each new well is productive or they are doomed?
EB: The size of the company shouldn't have anything to do with it. Iteration is something that needs to happen after you get new information. The question is not, "do I need to iterate now that we have drilled a few more wells?", but "how does this new information change my previous work?" Perhaps the interpretation was too rigid — too precise — to begin with. If the interpreter sees her work as something that evolves towards a more complete picture, she needn't be afraid of changing her mind if new information proves us to be incorrect. Depth migration, for example, exemplifies this approach. Hopefully more conceptual and qualitative aspects of subsurface work can adopt it as well.
SC: The present day workflows for seismic interpretation for unconventional resources demand more than the usual practices followed for the conventional exploration and development. Could you comment on how these are changing?
EB: With unconventionals, seismic interpreters are looking for different things. They aren't looking for reservoirs, they are looking for suitable locations to create reservoirs. Seismic technologies that estimate the state of stress will become increasingly important, and interpreters will need to work in close contact to geomechanics. Also, microseismic monitoring and time-lapse technologies tend to push interpreters into the thick of the operations, which allow them to study how the properties of the earth change according to operations. What a perfect place for iterative workflows.

You can read the other interviews and Evan's essay in the magazine, or buy the book! (You'll find it in Amazon's stores too.) It's a great introduction to who applied geophysicists are, and what sort of problems they work on. Read more about it.
Join CSEG to catch more of these interviews as they come out.

















 Except where noted, this content is licensed
Except where noted, this content is licensed