
90 years of well logs
/Today is the 90th anniversary of the first well log. On 5 September 1927, three men from Schlumberger logged the Diefenbach [sic] well 2905 at Dieffenbach-lès-Wœrth in the Pechelbronn heavy oil field in the Alsace region of France.

The site of the Diefenbach 2905 well. © Google, according to terms.

The geophysical services company Société de Prospection Électrique (Processes Schlumberger), or PROS, had only formed in July 1926 but already had sixteen employees. Headquartered in Paris at 42, rue Saint-Dominique, the company was attempting to turn its resistivity technology to industrial applications, especially mining and petroleum. Having had success with horizontal surface measurements, the Diefenbach well was the first attempt to measure resistivity in a wellbore. PROS went on to become Schlumberger.
The resistivity prospecting system had been designed by the Schlumberger brothers, Conrad (1878–1936, a professor at École des Mines) and Maurice (1884–1953, a mining engineer), over the period from about 1912 until 1923. The task of adapting the technology was given to Henri Doll (1902–1991), Conrad's son-in-law since 1923, and the Alsatian well was to be the first field test of the so-called "electrical coring" method. The client was Deutsche Erdöl Aktiengesellschaft, now DEA of Hamburg, Germany.
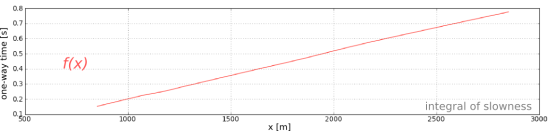
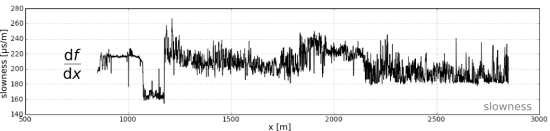
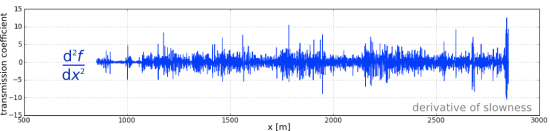
As far as I can tell, the well — despite usually being called "the Pechelbronn well" — was located at the site of a monument at the intersection of Route de Wœrth with Rue de Preuschdorf in Dieffenbach-lès-Wœrth, about 3 km west of Merkwiller-Pechelbronn. Henri Doll logged the well with Roger Jost and Charles Scheibli. Using rudimentary equipment, they logged about 145 m of the 488-metre hole, starting at 279 m MD, taking a reading every metre and plotting the log by hand. Yesterday I digitized this log; download it in LAS format here.

The story of what the Schlumberger brothers and Henri Doll achieved is fascinating; I recommend reading Don Hill's brief history (2012) — it's free to read at Wiley. The period of invention that followed the Pechelbronn success was inspiring.
If you're looking at well logs today, take a second to thank Conrad, Maurice, and Henri for their remarkable idea.
PS If you're interested in petroleum history, the AOGHS page This Week is worth a look.
The French television programme Midi en France recorded this segment about the Pechelbronn field in 2014. The narration is in French, "The fields of maize gorge on sunshine, the pumps on petroleum...", but there are some nice pictures to look at.
References and bibliography
Clapp, Frederick G (1932). Oil and gas possibilities of France. AAPG Bulletin 16 (11), 1092–1143. Contains a good history of exploration and production from the Oligocene sands in Pechelbronn, up to about 1931 (the field produced up to 1970). AAPG Datapages.
Delacour, Jacques (2003). Une technique de prospection minière et pétrolière née en Pays d'Auge. SABIX 34, September 2003. Available online.
École des Mines page on Conrad Schlumberger at annales.org.
Hill, DG (2012). Appendix A: Historical Review (Milestone Developments in Petrophysics). In: Buryakovsky, L, Chilingar, GV, Rieke, HH, and Shin, S (2012). Petrophysics: Fundamentals of the Petrophysics of Oil and Gas Reservoirs, John Wiley & Sons, Inc., Hoboken, NJ, USA. doi: 10.1002/9781118472750.app1. A nice potted history of well logging, including important dates.
Musée Français du Pétrole website, http://www.musee-du-petrole.com/historique/
Pike, B and Duey, R (2002). Logging history rich with innovation. Hart's E&P Magazine. September 2002. Available online. Interesting article, but beware: there are one or two inaccuracies in this article, and I believe the image of the well log is incorrect.












 Except where noted, this content is licensed
Except where noted, this content is licensed