
Great geophysicists #4: Fermat
/This Friday is Pierre de Fermat's 411th birthday. The great mathematician was born on 17 August 1601 in Beaumont-de-Lomagne, France, and died on 12 January 1665 in Castres, at the age of 63. While not a geophysicist sensu stricto, Fermat made a vast number of important discoveries that we use every day, including the principle of least time, and the foundations of probability theory.
Fermat built on Heron of Alexandria's idea that light takes the shortest path, proposing instead that light takes the path of least time. These ideas might seem equivalent, but think about anisotropic and inhomogenous media. Fermat continued by deriving Snell's law. Let's see how that works.
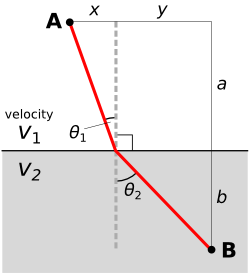 We start by computing the time taken along a path:
We start by computing the time taken along a path:
Then we differentiate with respect to space. This effectively gives us the slope of the graph of time vs distance.
We want to minimize the time taken, which happens at the minimum on the time vs distance graph. At the minimum, the derivative is zero. The result is instantly recognizable as Snell's law:
Maupertuis's generalization
The principle is a core component of the principle of least action in classical mechanics, first proposed by Pierre Louis Maupertuis (1698–1759), another Frenchman. Indeed, it was Fermat's handling of Snell's law that Maupertuis objected to: he didn't like Fermat giving preference to least time over least distance.
Maupertuis's generalization of Fermat's principle was an important step. By the application of the calculus of variations, one can derive the equations of motion for any system. These are the equations at the heart of Newton's laws and Hooke's law, which underlie all of the physics of the seismic experiment. So, you know, quite useful.
Probably very clever
 It's so hard to appreciate fundamental discoveries in hindsight. Together with Blaise Pascal, he solved basic problems in practical gambling that seem quite straightforward today. For example, Antoine Gombaud, the Chevalier de Méré, asked Pascal: why is it a good idea to bet on getting a 1 in four dice rolls, but not on a double-1 in twenty-four? But at the time, when no-one had thought about analysing problems in terms of permutations and combinations before, the solutions were revolutionary. And profitable.
It's so hard to appreciate fundamental discoveries in hindsight. Together with Blaise Pascal, he solved basic problems in practical gambling that seem quite straightforward today. For example, Antoine Gombaud, the Chevalier de Méré, asked Pascal: why is it a good idea to bet on getting a 1 in four dice rolls, but not on a double-1 in twenty-four? But at the time, when no-one had thought about analysing problems in terms of permutations and combinations before, the solutions were revolutionary. And profitable.
For setting Snell's law on a firm theoretical footing, and introducing probability into the world, we say Pierre de Fermat (pictured here) is indeed a father of geophysics.




















 Except where noted, this content is licensed
Except where noted, this content is licensed