 by Jelena Markov and Tom Horrocks
by Jelena Markov and Tom Horrocks
Jelena is a postgraduate student and Tom is a research assistant at the University of Western Australia, Perth. They competed in the recent RIIT Unearthed hackathon, and kindly offered to tell us all about it. Thank you, Jelena and Tom!
 Two weeks ago Perth coworking space Spacecubed hosted a unique 54-hour-long hackathon focused on the mining industry. Most innovations in the mining industry are the result of long-term strategic planning in big mining companies, or collaboration with university groups. In contrast, the Unearthed hackathon provided different perspectives on problems in the mining domain by giving 'outsiders' a chance to work on industry problems.
Two weeks ago Perth coworking space Spacecubed hosted a unique 54-hour-long hackathon focused on the mining industry. Most innovations in the mining industry are the result of long-term strategic planning in big mining companies, or collaboration with university groups. In contrast, the Unearthed hackathon provided different perspectives on problems in the mining domain by giving 'outsiders' a chance to work on industry problems.
The event attracted web-designers, software developers, data gurus, and few geology and geophysics geeks, all of whom worked together on data — both open and proprietary from the Western Australian Government and industry respectively — to deliver time-constrained solutions to problems in the mining domain. There were around 100 competitors divided into 18 teams, but just one underlying question: can web-designers and software developers create solutions that compete, on an innovative level, with those from the R&D divisions of mining companies? Well, according to panel of mining executives and entrepreneurs, they can.
Safe, seamless shutdown
The majority of the teams chose to work on logistic problems in mining production. For example, the Stockphiles worked on a Rio Tinto problem about how to efficiently and safely shut down equipment without majorly disturbing the overall system. Their solution used Directed Acyclic Graphs as the basis for an interactive web-based interface that visualised the impacted parts of the system. Outside of the mining production domain, however, two teams tackled problems focused on geology and geophysics...
Geoscience hacking
The team Ultramafia used augmented reality and cloud-based analysis to visualize geological mapping, with the underlying theme of the smartphone replacing the geological hammer, and also the boring task of joint logging!
The other team in this domain — and the team we were part of — was 50 Grades of Shale...

The team consisted of three PhD students and three staff members from the Centre for Exploration Targeting at the UWA. We created an app for real-time downhole petrophysical data analysis — dubbed Wireline Spelunker — that automatically classifies lithology types from wireline logs and correlates user-selected log segments across the drill holes. We used some public libraries for machine learning and signal analysis algorithms, and within 54 hours the team had implemented a workflow and interface, using data from the government database.
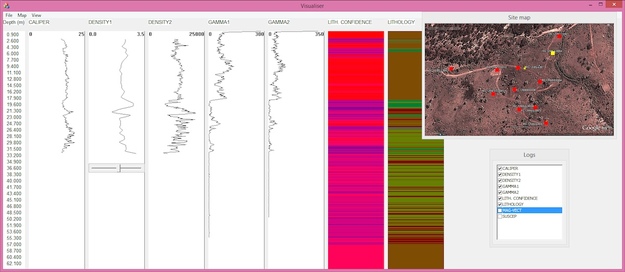
The boulder detection problem
The first prize, a 1 oz gold medal, was awarded to Applied Mathematics, who came up with an extraordinary use of accelerometers. They worked on Rio Tinto's 'boulder detection' problem — early detection of a large rocks loaded into mining trucks in order to prevent crusher malfunctions later in the process, which could ultimately cost $250,000 per hour in lost revenue. The team's solution was to detect large boulders by measuring the truck's vibrations during loading.
Second and third prizes went to Pit IQ and The Froys respectively. Both teams worked on data visualization problems on the mine site, and came up with interactive mobile dashboards.
A new role for Perth?
Besides having a chance to tackle problems that are costing the mining industry millions of dollars a year, this event has demonstrated that Perth is not just a mining hub but also has potential for something else.
This potential is recognized by event organizers Resources Innovation through Information Technology — Zane, Justin, Paul, and Kevin. They see potential in Perth as a centre for tech start-ups focused on the resource industry. Evidently, the potential is huge.
Follow Jelena on Twitter

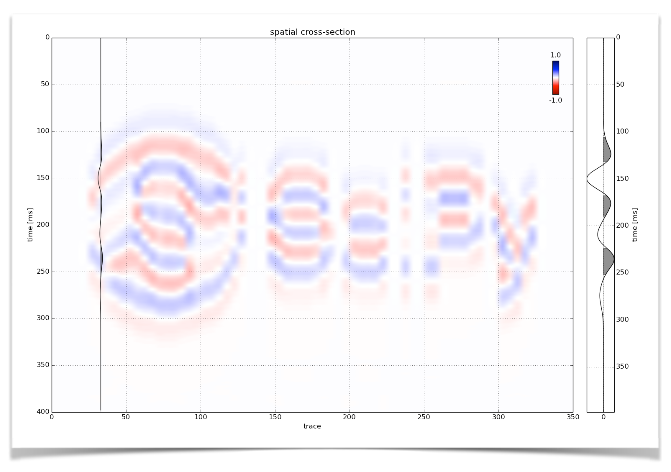 Wednesday was geophysics day at SciPy 2014, the conference for scientific Python in Austin. We had a mini-symposium in the afternoon, with 4 talks and 2 lightning talks about posters.
Wednesday was geophysics day at SciPy 2014, the conference for scientific Python in Austin. We had a mini-symposium in the afternoon, with 4 talks and 2 lightning talks about posters. There have been so many other highlights at this amazing conference that I can't resist sharing a couple of the non-geophysical gems...
There have been so many other highlights at this amazing conference that I can't resist sharing a couple of the non-geophysical gems...










 Except where noted, this content is licensed
Except where noted, this content is licensed