
A long weekend of Atlantic geology
/The Atlantic Geoscience Society Colloquium was hosted by Acadia University in Wolfville, Nova Scotia, this past weekend. It was the 50th Anniversay meeting, and attracted a crowd of about 175 geoscientists. A few members were able to reflect and tell stories first-hand of the first meeting in 1964.
It depends which way you slice it
Nova Scotia is one of the best places for John Waldron to study deformed sedimentary rocks of continental margins and orogenic belts. Being the anniversary, John traced the timeline of tectonic hypotheses over the last 50 years. From his kinematic measurements of Nova Scotia rocks, John showed the complexity of transtensional tectonics. It is easy to be fooled: you will see contraction features in one direction, and extension structures in another direction. It all depends which way you slice it. John is a leader in visualizing geometric complexity; just look at this animation of piecing together a coal mine in Stellarton. Oh, and he has a cut and fold exercise so that you can make your own Grand Canyon!
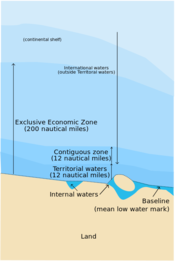 The application of the Law of the Sea
The application of the Law of the Sea
In September 2012 the Bedford Institute of Oceanography acquired some multibeam bathymetric data and applied geomorphology equations to extend Canada's boundaries in the Atlantic Ocean. Calvin Campbell described the cruise as like puttering from Halifax to Victoria and back at 20 km per hour, sending a chirp out once a minute, each time waiting for it to go out 20 kilometres and come back.
The United Nation's Convention on the Law of the Sea (UNCLOS) was established to define the rights and responsibilities of nations in their use of the world's oceans, establishing guidelines for businesses, the environment, and the management of marine natural resources. A country is automatically entitled to any natural resources found within a 200 nautical mile limit of its coastlines, but can claim a little bit more if they can prove they have sedimentary basins beyond that.
Practicing the tools of the trade
Taylor Campbell, applied a post-stack seismic inversion workflow to the Penobscot 3D survey and wells. Compared to other software talks I have seen in industry, Taylor's was a quality piece of integrated technical work. This is even more commendable considering she is an undergraduate student at Dalhousie. My only criticism, which I shared with her after the talk was over, was that the work lacked a probing question. It would have served as an anchor for the work, and I think is one of the critical distinctions between scientific pursuits and engineering.
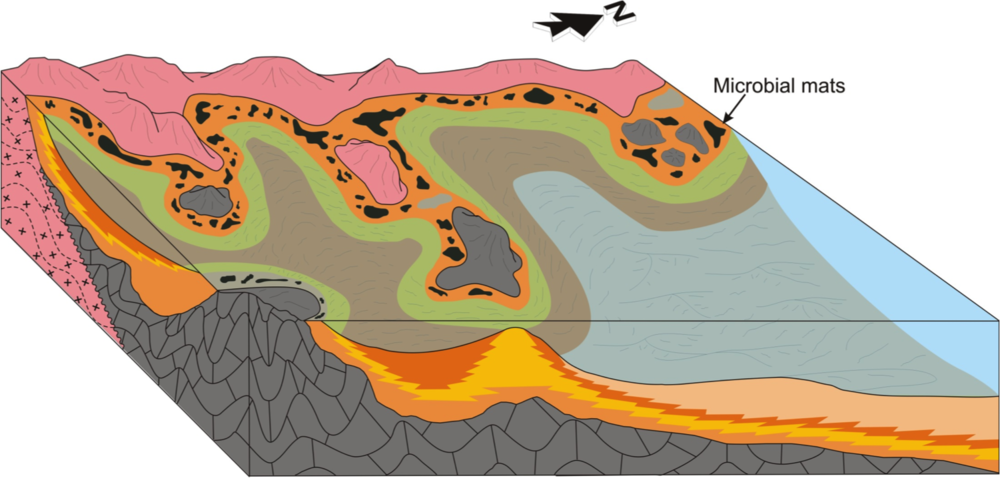 Image courtesy of Justin Drummond, 2014, personal communication, from his expanded abstract presented at GSA 2013.
Image courtesy of Justin Drummond, 2014, personal communication, from his expanded abstract presented at GSA 2013.
Practicing rational inquiry
Justin Drummond's work, on the other hand, started with a nugget of curiosity: How did the biogeochemical cycling of phosphorite change during the Neoproterozoic? Justin's anchoring question came first, only then could he think about the methods, technologies and tools he needed to employ, applying sedimentology, sequence stratigraphy, and petrology to investigate phosphorite accumulation in the Sete Lagoas Formation. He won the award for Best Graduate Student presentation at the conference.
It is hard to know if he won because his work was so good, or if it was because of his impressive vocabulary. He put me in mind of what Rex Murphy would sound like if he were a geologist.
The UNCLOS illustration is licensed CC-BY-SA, by Wikipedia users historicair and MJSmit.

















 Except where noted, this content is licensed
Except where noted, this content is licensed {kind=link}