
Corendering attributes and 2D colourmaps
/The reason we use colourmaps is to facilitate the human eye in interpreting the morphology of the data. There are no hard and fast rules when it comes to choosing a good colourmap, but a poorly chosen colourmap can make you see features in your data that don't actually exist.

Colourmaps are typically implemented in visualization software as 1D lookup tables. Given a value, what colour should I plot it? But most spatial data is multi-dimensional, and it's useful to look at more than one aspect of the data at one time. Previously, Matt asked, "how many attributes can a seismic interpreter show with colour on a single display?" He did this by stacking up a series of semi-opaque layers, each one assigned its own 1D colourbar.
Another way to add more dimensions to the display is corendering. This effectively adds another dimension to the colourmap itself: instead of a 1D colour line for a single attribute, for two attributes we're defining a colour square; for 3 attributes, a colour cube, and so on.
Let's illustrate this by looking at a time-slice through a portion of the F3 seismic volume. A simple way of displaying two attributes is to decrease the opacity of one, and lay it on top of the other. In the figure below, I'm setting the opacity of the continuity to 75% in the third panel. At first glance, this looks pretty good; you can see both attributes, and because they have different hues, they complement each other without competing for visual bandwidth. But the approach is flawed. The vividness of each dataset is diminished; we don't see the same range of colours as we do in the colour palette shown above.

Overlaying one map on top of the other is one way to look at multiple attributes within a scene. It's not ideal however.
Instead of overlaying maps, we can improve the result by modulating the lightness of the amplitude image according to the magnitude of the continuity attribute. This time the corendered result is one image, instead of two. I prefer it, because it preserves the original colours we see in the amplitude image. If anything, it seems to deepen the contrast:

The lightness value of the seismic amplitude time slice has been modulated by the continuity attribute.
Such a composite display needs a two-dimensional colormap for a legend. Just as a 1D colourbar, it's also a lookup table; each position in the scene corresponds to a unique pair of values in the colourmap plane.

We can go one step further. Say we want to emphasize only the largest discontinuities in the data. We can modulate the opacity with a non-linear function. In this example, I'm using a sigmoid function:
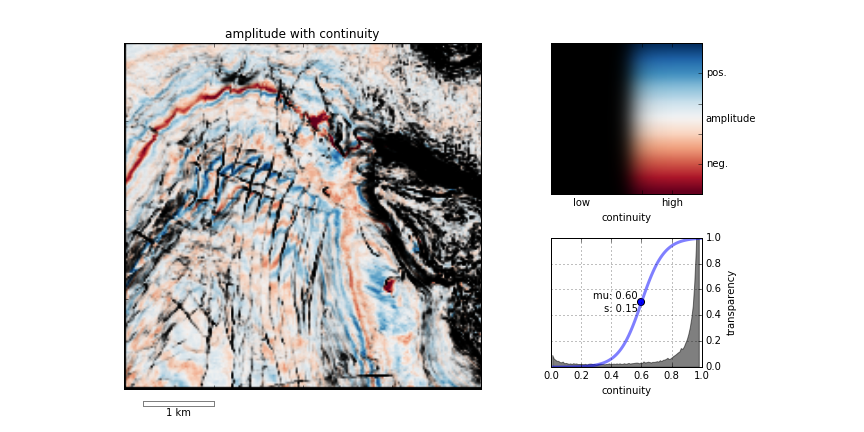
In order to achieve this effect in most conventional software, you usually have to copy the attribute, colour it black, apply an opacity curve, then position it just above the base amplitude layer. Software companies call this workaround a 'workflow'.
Are there data visualizations you want to create, but you're stuck with software limitations? In a future post, I'll recreate some cool co-rendering effects; like bump-mapping, and hill-shading.

To view and run the code that I used in creating the images for this post, grab the iPython/Jupyter Notebook.
You can do it too!
If you're in Calgary, Houston, New Orleans, or Stavanger, listen up!
If you'd like to gear up on coding skills and explore the benefits of scientific computing, we're going to be running the 2-day version of the Geocomputing Course several times this fall in select cities. To buy tickets or for more information about our courses, check out the courses page.
None of these times or locations good for you? Consider rounding up your colleagues for an in-house training option. We'll come to your turf, we can spend more than 2 days, and customize the content to suit your team's needs. Get in touch.













































 Except where noted, this content is licensed
Except where noted, this content is licensed