
SEG-Y Rev 2 again: little-endian is legal!
/Big news! Little-endian byte order is finally legal in SEG-Y files.
That's not all. I already spilled the beans on 64-bit floats. You can now have up to 18 quintillion traces (18 exatraces?) in a seismic line. And, finally, the hyphen confusion is cleared up: it's 'SEG-Y', with a hyphen. All this is spelled out in the new SEG-Y specification, Revision 2.0, which was officially released yesterday after at least five years in the making. Congratulations to Jill Lewis, Rune Hagelund, Stewart Levin, and the rest of the SEG Technical Standards Committee.
Back up a sec: what's an endian?
Whenever you have to think about the order of bytes (the 8-bit chunks in a 'word' of 32 bits, for example) — for instance when you send data down a wire, or store bytes in memory, or in a file on disk — you have to decide if you're Roman Catholic or Church of England.
What?
It's not really about religion. It's about eggs.
In one of the more obscure satirical analogies in English literature, Jonathan Swift wrote about the ideological tussle between between two factions of Lilliputians in Gulliver's Travels (1726). The Big-Endians liked to break their eggs at the big end, while the Little-Endians preferred the pointier option. Chaos ensued.
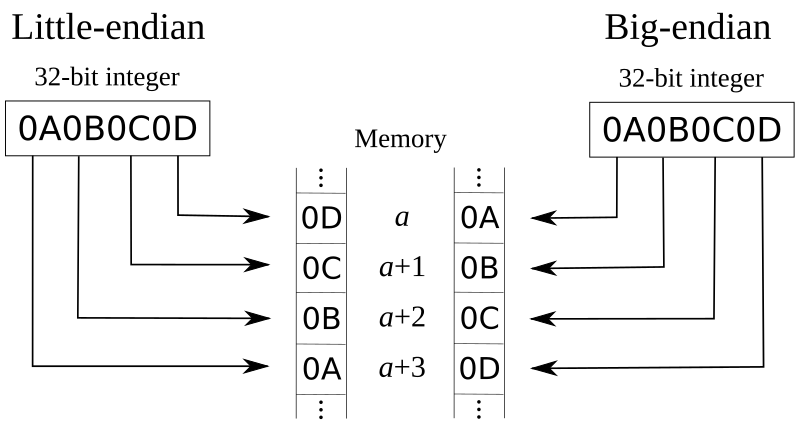
Two hundred and fifty years later, Danny Cohen borrowed the terminology in his 1 April 1980 paper, On Holy Wars and a Plea for Peace — in which he positioned the Big-Endians, preferring to store the big bytes first in memory, against the Little-Endians, who naturally prefer to store the little ones first. Big bytes first is how the Internet shuttles data around, so big-endian is sometimes called network byte order. The drawing (right) shows how the 4 bytes in a 32-bit 'word' (the hexadecimal codes 0A, 0B, 0C and 0D) sit in memory.
Because we write ordinary numbers big-endian style — 2017 has the thousands first, the units last — big-endian might seem intuitive. Then again, lots of people write dates as, say, 31-03-2017, which is analogous to little-endian order. Cohen reviews the computational considerations in his paper, but really these are just conventions. Some architectures pick one, some pick the other. It just happens that the x86 architecture that powers most desktop and laptop computers is little-endian, so people have been illegally (and often accidentally) writing little-endian SEG-Y files for ages. Now it's actually allowed.
Still other byte orders are possible. Some processors, notably ARM and other RISC architectures, are middle-endian (aka mixed endian or bi-endian). You can think of this as analogous to the month-first American date format: 03-31-2017. For example, the two halves of a 32-bit word might be reversed compared to their 'pure' endian order. I guess this is like breaking your boiled egg in the middle. Swift did not tell us which religious denomination these hapless folks subscribe to.
OK, that's enough about byte order
I agree. So I'll end with this handy SEG-Y cheatsheet. Click here for the PDF.

References and acknowledgments
Cohen, Danny (April 1, 1980). On Holy Wars and a Plea for Peace. IETF. IEN 137. "...which bit should travel first, the bit from the little end of the word, or the bit from the big end of the word? The followers of the former approach are called the Little-Endians, and the followers of the latter are called the Big-Endians." Also published at IEEE Computer, October 1981 issue.
Thumbnail image: “Remember, people will judge you by your actions, not your intentions. You may have a heart of gold -- but so does a hard-boiled egg.” by Kate Ter Haar is licensed under CC BY 2.0






















 Except where noted, this content is licensed
Except where noted, this content is licensed