I set out to detect patterns in images, with the conviction that they are diagnostic of more telling physical properties of the media. Tea towel textures can indicate absorbency, durability, state of wear and tear, etc. Seismic textures can indicate things like depositional environment, degree of deformation, lithologic content, and so on:
Facies: A rock or stratified body distinguished from others by its appearance or composition.
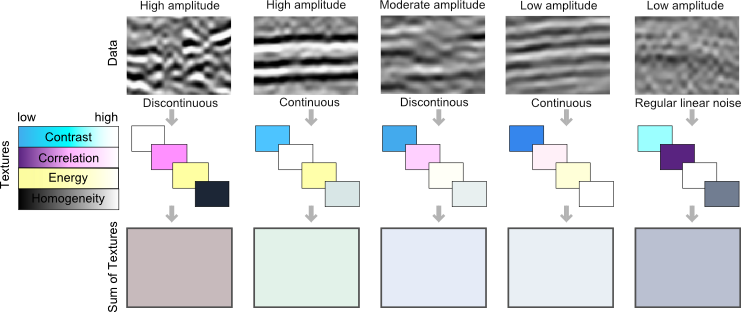
Facies are clusters distinguishable in all visual media. Geophysicists shouldn't be afraid of using the word normally reserved by geologists—seismic facies. In the seismic case, instead of lithology, grain size, bedding patterns, and so on, we are using attributes such as amplitude, energy, coherency, and Haralick textures for classification.
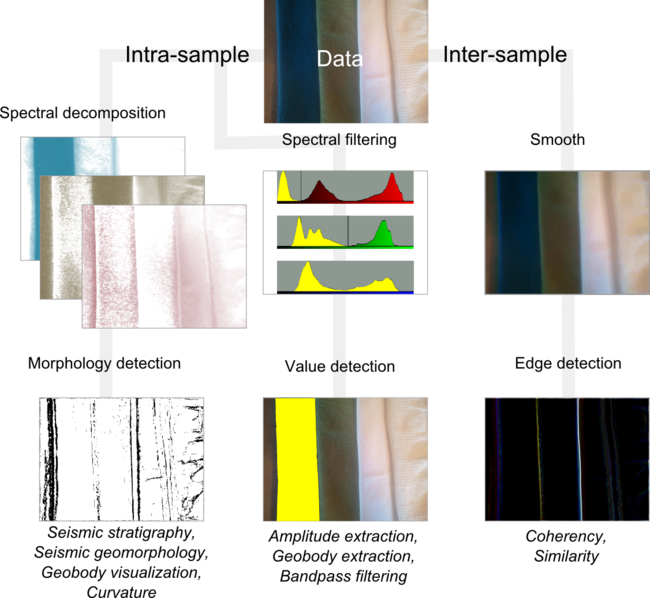
The brain is good at pattern recognition and picking out subtleties. I can assign facies to the input data (A), based on on hues (B), or patterns (C). I can also count objects (D), interpret boundaries (E), and identify poorly resolved regions of an image (F) caused by shadows or noise. I can even painstakingly draw the pockmarks or divets in the right hand teatowel (G). All of these elements can be simultaneously held in the mind of the viewer and comprise what we naturally perceive as the properties of visual media. Isolating, extracting, and illustrating these visual features by hand remains tedious.

I am not interested in robot vision so computers can replace geophysical interpreters, but I am interested in how image classification can be used to facilitate, enrich, and expedite the interpretive process. You can probably already think of attributes we can use to coincide with this human interpretation from the examples I gave in a previous post.
Identifying absorbency
Let's set an arbitrary goal of classifying the ability to soak up water, or absorbency. Surely a property of interest to anyone studying porous media. Because absorbency is a media-property, not an optical property (like colour) or a boundary property (like edges), it makes sense to use texture classification. From the input image, I can count 5 different materials, each with a distinct pattern. The least tractable might be the rightmost fabric which has alternating waffle-dimple segments, troublesome shadows and contours, and patterns at two different scales. The test of success is seeing how this texture classification compares to the standard approach of visual inspection and manual picking.

I landed on using 7 classes for this problem. Two for the white tea-towels, two for the green tea-towel, one for the blue, and one that seems to be detecting shadows (shown in dark grey). Interestingly, the counter top on the far left falls into the same texture class as the green tea-towel. Evidence that texture alone isn't a foolproof proxy for absorbency. To improve the classification, I would need to allow more classes (likely 8 or 9).
It seems to me that the manual picks match the classification quite well. The picks lack detail, as with any interpretation, but they also lack noise. On the contrary, there are some locations where the classification has failed. It stuggles in low-light and over-exposed regions.
If you are asking, "is one approach better than the other?", you are asking the wrong question. These are not mutually exclusive approaches. The ideal scenario is one which uses these methods in concert for detecting geologic features in the fabric of seismic data.

 Click to download slides with notes!Interpretation has become an empty word in geoscience. Like so many other buzzwords, instead of being descriptive and specific jargon, it seems that everyone has their own definition or (mis)use of the word. If interpretation is the art and process of making mindful leaps between unknowns in data, I say, let's quantify to the best of our ability the data we have. Your interpretation should be iteratable, it should be systematic, and it should be cast as an algorithm. It should be verifiable, it should be reproducible. In a word, scientific.
Click to download slides with notes!Interpretation has become an empty word in geoscience. Like so many other buzzwords, instead of being descriptive and specific jargon, it seems that everyone has their own definition or (mis)use of the word. If interpretation is the art and process of making mindful leaps between unknowns in data, I say, let's quantify to the best of our ability the data we have. Your interpretation should be iteratable, it should be systematic, and it should be cast as an algorithm. It should be verifiable, it should be reproducible. In a word, scientific. 















 Except where noted, this content is licensed
Except where noted, this content is licensed