 Julia is the most talked-about language in the scientific Python community. Well, OK, maybe second to Python... but only just. I noticed this at SciPy in July, and again at EuroSciPy last weekend.
Julia is the most talked-about language in the scientific Python community. Well, OK, maybe second to Python... but only just. I noticed this at SciPy in July, and again at EuroSciPy last weekend.
As promised, here's my attempt to explain why scientists are so excited about it.
Why is everyone so interested in Julia?
At some high level, Julia seems to solve what Steven Johnson (MIT) described at EuroSciPy on Friday as 'the two-language problem'. It's also known as Outerhout's dichotomy. Basically, there are system languages (hard to use, fast), and scripting languages (easy to use, slow). Attempts to get the best of boths worlds have tended to result in a bit of a mess. Until Julia.
Really though, why?
Cheap speed. Computer scientists adore C because it's rigorous and fast. Scientists and web developers worship Python because it's forgiving and usually fast enough. But the trade-off has led to various cunning ploys to get the best of both worlds, e.g. PyPy and Cython. Julia is perhaps the cunningest ploy of all, achieving speeds that compare with C, but with readable code, dynamic typing, garbage collection, multiple dispatch, and some really cool tricks like Unicode variable names that you enter in pure LaTeX. And check out this function definition shorthand:
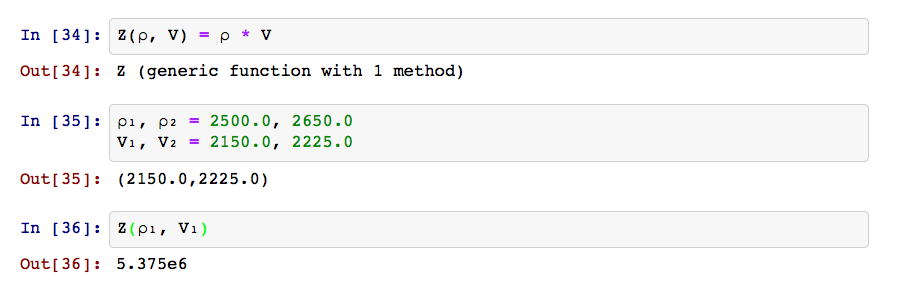
Why is Julia so fast?
Machines don't understand programming languages — the code written by humans has to be translated into machine language in a process called 'compiling'. There are three approaches:
Compiling makes languages fast, because the executed code is tuned to the task (e.g. in terms of the types of variables it handles), and to the hardware it's running on. Indeed, it's only by building special code for, say, integers, that compiled languages achieve the speeds they do.
Julia is compiled, like C or Fortran, so it's fast. However, unlike C and Fortran, which are compiled before execution, Julia is compiled at runtime ('just in time' for execution). So it looks a little like an interpreted language: you can write a script, hit 'run' and it just works, just like you can with Python.
You can even see what the generated machine code looks like:

Don't worry, I can't read it either.
But how is it still dynamically typed?
Because the compiler can only build machine code for specific types — integers, floats, and so on — most compiled languages have static typing. The upshot of this is that the programmer has to declare the type of each variable, making the code rather brittle. Compared to dynamically typed languages like Python, in which any variable can be any type at any time, this makes coding a bit... tricky. (A computer scientist might say it's supposed to be tricky — you should know the type of everything — but we're just trying to get some science done.)
So how does Julia cope with dynamic typing and still compile everything before execution? This is the clever bit: Julia scans the instructions and compiles for the types it finds — a process called type inference — then makes the bytecode, and caches it. If you then call the same instructions but with a different type, Julia recompiles for that type, and caches the new bytecode in another location. Subsequent runs use the appropriate bytecode, with recompilation.
 Metaprogramming
Metaprogramming
It gets better. By employing metaprogramming — on-the-fly code generation for special tasks — it's possible for Julia to be even faster than highly optimized Fortran code (right), in which metaprogramming is unpleasantly difficult. So, for example, in Fortran one might tolerate a relatively slow loop that can only be avoided with code generation tricks; in Julia the faster route is much easier. Here's Steven's example.
Interoperability and parallelism
 It gets even better. Julia has been built with interoperability in mind, so calling C — or Python — from inside Julia is easy. Projects like Jupyter will only push this further, and I expect Julia to soon be the friendiest way to speed up that stubborn inner NumPy loop. And I'm told a lot of thoughtful design has gone into Julia's parallel processing libraries... I have never found an easy way into that world, so I hope it's true.
It gets even better. Julia has been built with interoperability in mind, so calling C — or Python — from inside Julia is easy. Projects like Jupyter will only push this further, and I expect Julia to soon be the friendiest way to speed up that stubborn inner NumPy loop. And I'm told a lot of thoughtful design has gone into Julia's parallel processing libraries... I have never found an easy way into that world, so I hope it's true.
I'm not even close to being able to describe all the other cool things Julia, which is still a young language, can do. Much of it will only be of interest to 'real' programmers. In many ways, Julia seems to be 'Python for C programmers'.
If you're really interested, read Steven's slides and especially his notebooks. Better yet, just install Julia and IJulia, and play around. Here's another tutorial and a cheatsheet to get you started.

 Carl Friedrich Gauss was born on 30 April 1777 in Braunschweig (Brunswick), and died at the age of 77 on 23 February 1855 in Göttingen. He was a mathematician, you've probably heard of him; he even has his own Linnean handle: Princeps mathematicorum, or Prince of mathematicians (I assume it's the royal kind, not the Purple Rain kind — ba dum tss).
Carl Friedrich Gauss was born on 30 April 1777 in Braunschweig (Brunswick), and died at the age of 77 on 23 February 1855 in Göttingen. He was a mathematician, you've probably heard of him; he even has his own Linnean handle: Princeps mathematicorum, or Prince of mathematicians (I assume it's the royal kind, not the Purple Rain kind — ba dum tss). He proved the fundamental theorems of algebra and arithmetic. No big deal.
He proved the fundamental theorems of algebra and arithmetic. No big deal.















 Except where noted, this content is licensed
Except where noted, this content is licensed