
The (bad) stuff of legend
/What is a legend? Merriam–Webster says:
- A story from the past that is believed by many people but cannot be proved to be true.
- An explanatory list of the symbols on a map or chart.
I think we can combine these:
An explanatory list from the past that is believed by many to be useful but which cannot be proved to be.
Maybe that goes too far, sometimes you need a legend. But often, very often, you don't. At the very least, you should always try hard to make the legend irrelevant. Why, and how, can you do this?
A case study
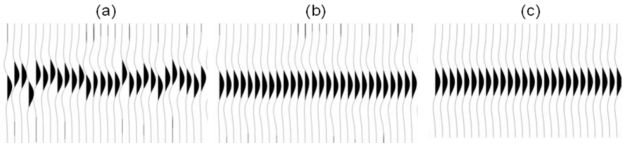
On the right is a non-scientific caricature of a figure from a paper I just finished reviewing for Geophysics. I won't give any more details because I don't want to pick on it unduly — lots of authors make the same mistakes.

Here are some of the things I think are confusing about this figure, detracting from the science in the paper.
- Making the reader cross-reference the line decoration with the legend makes it harder to make the comparison you're asking them to make. Just label the lines directly.
- Using unhelpful, generic names like 1, 2, and 3 for the models leads the reader into cross-reference Inception. The models were shown and explained on the previous page.
- Inception again: the models 1, 2, and 3 were shown in the previous figure parts (a), (b), and (c) respectively. So I had to cross-reference deeper still to really find out about them.
- The paper used colour elsewhere, so the use of black and white line decoration here seems unnecessary. There are other ways to ensure clarity if the paper is photocopied.
- Everything on the same visual plane, so to speak, so the chart cannot take any more detail, such as gridlines.
Getting better
I have tried to fix some of this in the version of the figure shown here. It's the same size as the original. The legend, such as it is, is now a visual key to the models. Careful juxtaposition of figures could obviate the need even for this extra key. The idea would be to use the colours and names of the models in every figure, to link them more intuitively.

The principles at work:
- Reduce the fatigue of reading by labeling things directly.
- Avoid using 'a' and 'b' or other generic names. Call the parts before and after, or 8 ms gate and 16 ms gate.
- Put things you want people to compare next to each other: models with data, output with input, etc.
- Use less ink for decoration, more ink for data. Gently direct the reader's attention.
I'm sure there are other improvements we could make. Do you have any tips to share for making better figures? Leave them in the comments.

Update, 30 Jan 2015
Some great comments came in today, and the point about black and white is well taken. Indeed, our 52 Things books are all black and white, and I end up transforming most images and figures to (I hope) make them clearer without colour. Here's how I'd do this figure in black and white.


















 Except where noted, this content is licensed
Except where noted, this content is licensed {kind=link}