Some new businesses go out and raise millions in capital before they do anything else. Not us — we only do what we can afford. Money makes you lazy. It's technical consulting on a shoestring!
If you're on a budget, open source is your best friend. More than this, it's important an open toolbox is less dependent on hardware and less tied to workflows. Better yet, avoiding large technology investments helps us avoid vendor lock-in, and the resulting data lock-in, keeping us more agile. And there are two more important things about open source:
- You know exactly what the software does, because you can read the source code
- You can change what the software does, becase you can change the source code
Anyone who has waited 18 months for a software vendor to fix a bug or add a feature, then 18 more months for their organization to upgrade the software, knows why these are good things.
So what do we use?
In the light of all this, people often ask us what software we use to get our work done.
Hardware Matt is usually on a dual-screen Apple iMac running OS X 10.6, while Evan is on a Samsung Q laptop (with a sweet solid-state drive) running Windows. Our plan, insofar as we have a plan, is to move to Mac Pro as soon as the new ones come out in the next month or two. Pure Linux is tempting, but Macs are just so... nice.
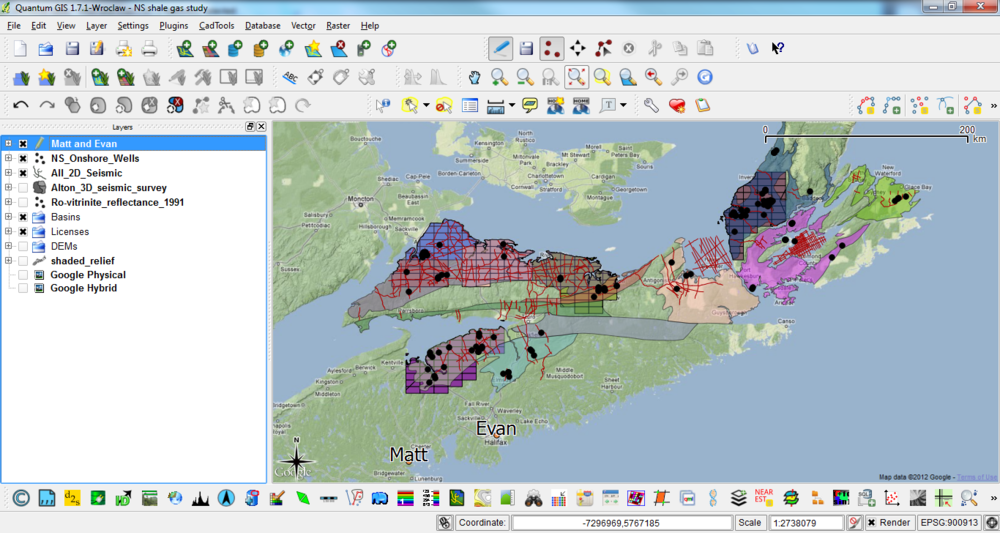
Geoscience interpretation dGB OpendTect, GeoCraft, Quantum GIS (above). The main thing we lack is a log visualization and interpretation tool. Beyond this, we don't use them much yet but Madagascar and GMT are plugged right into OpendTect. For getting started on stratigraphic charts, we use TimeScale Creator.
A quick aside, for context: when I sold Landmark's GeoProbe seismic interpretation tool, back in 2003 or so, the list price was USD140 000 per user, choke, plus USD25k per year in maintenance. GeoProbe is very powerful now (and I have no idea what it costs), but OpendTect is a much better tool that that early edition was. And it's free (as in speech, and as in beer).
 Geekery, data mining, analysis Our core tools for data mining are Excel, Spotfire Silver (an amazing but proprietary tool), MATLAB and/or GNU Octave, random Python. We use Gephi for network analysis, FIJI for image analysis, and we have recently discovered VISAT for remote sensing images. All our mobile app development has been in MIT AppInventor so far, but we're playing with the PhoneGap framework in Eclipse too.
Geekery, data mining, analysis Our core tools for data mining are Excel, Spotfire Silver (an amazing but proprietary tool), MATLAB and/or GNU Octave, random Python. We use Gephi for network analysis, FIJI for image analysis, and we have recently discovered VISAT for remote sensing images. All our mobile app development has been in MIT AppInventor so far, but we're playing with the PhoneGap framework in Eclipse too.
Writing and drawing Google Docs for words, Inkscape for vector art and composites, GIMP for rasters, iMovie for video, Adobe InDesign for page layout. And yeah, we use Microsoft Office and OpenOffice.org too — sometimes it's just easier that way. For managing references, Mendeley is another recent discovery — it is 100% awesome. If you only look at one tool in this post, look at this.
Collaboration We collaborate with each other and with clients via Skype, Dropbox, Google+ Hangouts, and various other Google tools (for calendars, etc). We also use wikis (especially SubSurfWiki) for asynchronous collaboration and documentation. As for social media, we try to maintain some presence in Google+, Facebook, and LinkedIn, but our main channel is Twitter.
Web This website is hosted by Squarespace for reliability and reduced maintenance. The MediaWiki instances we maintain (both public and private) are on MediaWiki's open source platform, running on Amazon's Elastic Compute servers for flexibility. An EC2 instance is basically an online Linux box, running Ubuntu and Bitnami's software stack, plus some custom bits and pieces. We are launching another website soon, running WordPress on Amazon EC2. Hover provides our domain names — an awesome Canadian company.
 Administrative tools Every business has some business tools. We use Tick to track our time — it's very useful when working on multiple projects, subscontractors, etc. For accounting we recently found Wave, and it is the best thing ever. If you have a small business, please check it out — after headaches with several other products, it's the best bean-counting tool I've ever used.
Administrative tools Every business has some business tools. We use Tick to track our time — it's very useful when working on multiple projects, subscontractors, etc. For accounting we recently found Wave, and it is the best thing ever. If you have a small business, please check it out — after headaches with several other products, it's the best bean-counting tool I've ever used.
If you have a geeky geo-toolbox of your own, we'd love to hear about it. What tools, open or proprietary, couldn't you live without?
Update on 2012-09-13 13:26 by Matt Hall
Just heard about this awesome list by John Stevenson, a postdoc at Edinburgh University, UK. Thanks to Jon Tennant, aka @protohedgehog, for the tip. Don't know how I missed that...

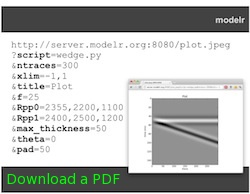 As at the PTTC Open Source workshop last year (Day 1, Day 2, and my presentation), I focused on mobile geocomputing — geoscience computing on mobile devices like phones and tablets. The main update to the talk was a segment on our new open source web application, Modelr. We haven't written about this project before, and I'd be the first to admit it's rather half-baked, but I wanted to plant the kernel of awareness now. We'll write more on it in the near future, but briefly: Modelr is a small web app that takes rock properties and model parameters, and generates synthetic seismic data images. We hope to use it to add functionality to our mobile apps, much as we already use Google's chart images. Stay tuned!
As at the PTTC Open Source workshop last year (Day 1, Day 2, and my presentation), I focused on mobile geocomputing — geoscience computing on mobile devices like phones and tablets. The main update to the talk was a segment on our new open source web application, Modelr. We haven't written about this project before, and I'd be the first to admit it's rather half-baked, but I wanted to plant the kernel of awareness now. We'll write more on it in the near future, but briefly: Modelr is a small web app that takes rock properties and model parameters, and generates synthetic seismic data images. We hope to use it to add functionality to our mobile apps, much as we already use Google's chart images. Stay tuned!













 Except where noted, this content is licensed
Except where noted, this content is licensed