
The road to Modelr: my EuroSciPy poster
/ At EuroSciPy recently, I gave a poster-ized version of the talk I did at SciPy. Unlike most of the other presentations at EuroSciPy, my poster didn't cover a lot of the science (which is well understood), or the code (which is esoteric).
At EuroSciPy recently, I gave a poster-ized version of the talk I did at SciPy. Unlike most of the other presentations at EuroSciPy, my poster didn't cover a lot of the science (which is well understood), or the code (which is esoteric).
Instead it focused on the advantages of spreading software via web applications, rather than only via source code, and on the challenges that we overcame — well, that we're still overcoming — to get our Modelr tool out there. I wanted other programmer-scientists to think about running some of their code as a web app for others to enjoy, but to be aware of the effort involved in doing this.
I've written before about my dislike of posters, though I'm told they are an important component at, say, the AGU Fall Meeting. I admit I do quite like the process of making them, and — on advice from Colin Purrington's useful page — I left a space on the poster for people to write comments or leave sticky notes. As a result, I heard about Docker, a lead I'll certainly follow up,
What's new in modelr
This wasn't part of the poster, but I might as well take the chance to let you know what we've updated recently:
- You can now add noise to models by specifying the signal:noise.
- Instead of automatic scaling, you can choose your own gain.
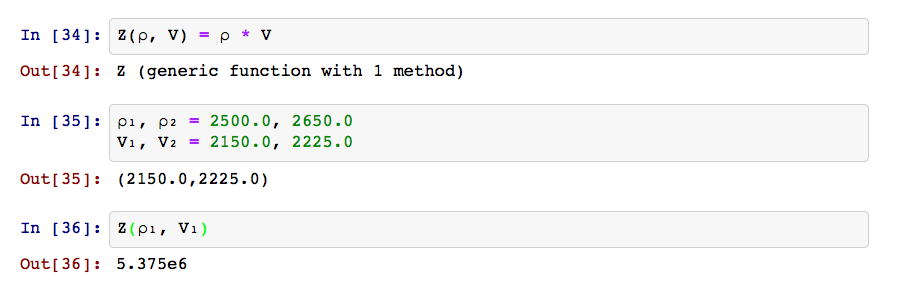
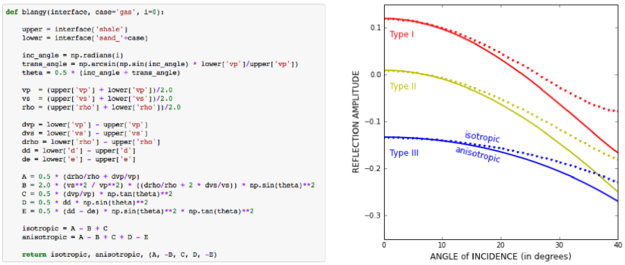
- The app now returns the elastic moduli of the rocks in the model.
- You can choose a spatial cross-section view or a space–offset–frequency view.
All of these features are now available to subscribers for only $9/month. Amazing value :)
Figshare
![]() I've stored my poster on Figshare, a data storage site and part of Macmillan's Digital Science effort. What I love about Figshare, apart from the convenience of cloud-based storage and easy access for others, is that every item gets a digital object identifier or DOI. You've probably seen these on journal articles. They're a bit like other persistent and unique IDs for publications, such as ISBNs for books, but the idea is to provide more interactivity by making it easily linkable: you can get to any object with a DOI by prepending it with "http://dx.doi.org/".
I've stored my poster on Figshare, a data storage site and part of Macmillan's Digital Science effort. What I love about Figshare, apart from the convenience of cloud-based storage and easy access for others, is that every item gets a digital object identifier or DOI. You've probably seen these on journal articles. They're a bit like other persistent and unique IDs for publications, such as ISBNs for books, but the idea is to provide more interactivity by making it easily linkable: you can get to any object with a DOI by prepending it with "http://dx.doi.org/".
Reference
Hall, M (2014). The road to modelr: building a commercial web app on an open source foundation. EuroSciPy, Cambridge, UK, August 29–30, 2014. Poster presentation. DOI:10.6084/m9.figshare.1151653






















 Except where noted, this content is licensed
Except where noted, this content is licensed