
Save the samples
/A long while ago I wrote about how to choose an image format, and then followed that up with a look at vector vs raster graphics. Today I wanted to revisit rasters (you might think of them as bitmaps, images, or photographs). Because a question that seems to come up a lot is 'what resolution should my images be?'
Forget DPI
When writing for print, it is common to be asked for a certain number of dots per inch, or dpi (or, equivalently, pixels per inch or ppi). For example, I've been asked by journal editors for images 'at least 200 dpi'. However, image files do not have an inherent resolution — they only have pixels. The resolution depends on the reproduction size you choose. So, if your image is 800 pixels wide, and will be reproduced in a 2-inch-wide column of print, then the final image is 400 dpi, and adequate for any purpose. The same image, however, will look horrible at 4 dpi on a 16-foot-wide projection screen.
![]() Rule of thumb: for an ordinary computer screen or projector, aim for enough pixels to give about 100 pixels per display inch. For print purposes, or for hi-res mobile devices, aim for about 300 ppi. If it really matters, or your printer is especially good, you are safer with 600 ppi.
Rule of thumb: for an ordinary computer screen or projector, aim for enough pixels to give about 100 pixels per display inch. For print purposes, or for hi-res mobile devices, aim for about 300 ppi. If it really matters, or your printer is especially good, you are safer with 600 ppi.
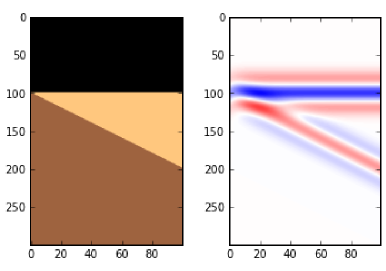
The effect of reducing the number of pixels in an image is more obvious in images with a lot of edges. It's clear in the example that downsampling a sharp image (a to c) is much more obvious than downsampling the same image after smoothing it with a 25-pixel Gaussian filter (b to d). In this example, the top images have 512 × 512 samples, and the downsampled ones underneath have only 1% of the information, at 51 × 51 samples (downsampling is a type of lossy compression).
Careful with those screenshots
The other conundrum is how to get an image of, say, a seismic section or a map.
What could be easier than a quick grab of your window? Well, often it just doesn't cut it, especially for data. Remember that you're only grabbing the pixels on the screen — if your monitor is small (or perhaps you're using a non-HD projector), or the window is small, then there aren't many pixels to grab. If you can, try to avoid a screengrab by exporting an image from one of the application's menus.
For seismic data, you'd like to capture sample as a pixel. This is not possible for very long or deep lines, because they don't fit on your screen. Since CGM files are the devil's work, I've used SEGY2ASCII (USGS Open File 2005–1311) with good results, converting the result to a PGM file and loading into Gimp.
 Large seismic lines are hard to capture without decimating the data. Rockall Basin. Image: BGS + Virtual Seismic Atlas.If you have no choice, make the image as large as possible. For example, if you're grabbing a view from your browser, maximize the window, turn off the bookmarks and other junk, and get as many pixels as you can. If you're really stuck, grab two or more views and stitch them together in Gimp or Inkscape.
Large seismic lines are hard to capture without decimating the data. Rockall Basin. Image: BGS + Virtual Seismic Atlas.If you have no choice, make the image as large as possible. For example, if you're grabbing a view from your browser, maximize the window, turn off the bookmarks and other junk, and get as many pixels as you can. If you're really stuck, grab two or more views and stitch them together in Gimp or Inkscape.
When you've got the view you want, crop the window junk that no-one wants to see (frames, icons, menus, etc.) and save as a PNG. Then bring the image into a vector graphics editor, and add scales, colourbars, labels, annotation, and other details. My advice is to do this right away, before you forget. The number of times I've had to go and grab a screenshot again because I forgot the colourbar...
The Lenna image is from Hall, M (2006). Resolution and uncertainty in spectral decomposition. First Break 24, December 2006, p 43-47.













 Except where noted, this content is licensed
Except where noted, this content is licensed