A few weeks ago I looked at the concept — or concepts — of brittleness. There turned out to be lots of ways of looking at it. We decided to call it a rock behaviour rather than a property. And we determined to look more closely at some different ways to define it. Here they are...
Some brittleness indices
There are lots of 'definitions' of brittleness in the literature. Several of them capture the relationship between compressive and tensile strength, σC and σT respectively. This is potentially useful, because we measure uniaxial compressive strength in the standard triaxial rig tests that have become routine in shale studies... but we don't usually find the tensile strength, because it's much harder to measure. This is unfortunate, because hydraulic fracturing is initially a tensile failure (though reactivation and other failure modes do occur — see Williams-Stroud et al. 2012).
Altindag (2003) gave the following three examples of different brittleness indices. In turn, they are the strength ratio, a sort of relative strength contrast, and the mean strength (his favourite):
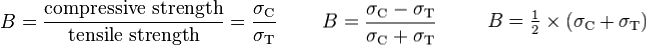
This is just the start, once you start digging, you'll find lots of others. Like Hucka & Das's (1974) round-up I wrote about last time, one thing they have in common is that they capture some characteristic of rock failure. That is, they do not rely on implicit rock properties.
Another point to note. Bažant & Kazemi (1990) gave a way to de-scale empirical brittleness measures to account for sample size — not surprisingly, this sort of 'real world adjustment' starts to make things quite complicated. Not so linear after all.
What not to do
The prevailing view among many interpreters is that brittleness is proportional to Young's modulus and/or Poisson's ratio, and/or a linear combination of these. We've reported a couple of times on what Lev Vernik (Marathon) thinks of the prevailing view: we need to question our assumptions about isotropy and linear strain, and computing shale brittleness from elastic properties is not physically meaningful. For one thing, you'll note that elastic moduli don't have anything to do with rock failure.
The Young–Poisson brittleness myth started with Rickman et al. 2008, SPE 115258, who presented a rather ugly representation of a linear relationship (I gather this is how petrophysicists like to write equations). You can see the tightness of the relationship for yourself in the data.

If I understand the notation, this is the same as writing B = 7.14E – 200ν + 72.9, where E is (static) Young's modulus and ν is (static) Poisson's ratio. It's an empirical relationship, based on the data shown, and is perhaps useful in the Barnett (or wherever the data are from, we aren't told). But, as with any kind of inversion, the onus is on you to check the quality of the calibration in your rocks.
What's left?
Here's Altindag (2003) again:
Brittleness, defined differently from author to author, is an important mechanical property of rocks, but there is no universally accepted brittleness concept or measurement method...
This leaves us free to worry less about brittleness, whatever it is, and focus on things we really care about, like organic matter content or frackability (not unrelated). The thing is to collect good data, examine it carefully with proper tools (Spotfire, Tableau, R, Python...) and find relationships you can use, and prove, in your rocks.
References
Altindag, R (2003). Correlation of specific energy with rock brittleness concepts on rock cutting. The Journal of The South African Institute of Mining and Metallurgy. April 2003, p 163ff. Available online.
Hucka V, B Das (1974). Brittleness determination of rocks by different methods. Int J Rock Mech Min Sci Geomech Abstr 10 (11), 389–92. DOI:10.1016/0148-9062(74)91109-7.
Rickman, R, M Mullen, E Petre, B Grieser, and D Kundert (2008). A practical use of shale petrophysics for stimulation design optimization: all shale plays are not clones of the Barnett Shale. SPE 115258, DOI: 10.2118/115258-MS.
Williams-Stroud, S, W Barker, and K Smith (2012). Induced hydraulic fractures or reactivated natural fractures? Modeling the response of natural fracture networks to stimulation treatments. American Rock Mechanics Association 12–667. Available online.

 As Matt wrote in March, he is editing a regular Tutorial column in SEG's The Leading Edge. I contributed the June edition, entitled Well-tie calculus. This is a brief synopsis only; if you have any questions about the workflow, or how to get started in Python, get in touch or come to my course.
As Matt wrote in March, he is editing a regular Tutorial column in SEG's The Leading Edge. I contributed the June edition, entitled Well-tie calculus. This is a brief synopsis only; if you have any questions about the workflow, or how to get started in Python, get in touch or come to my course. 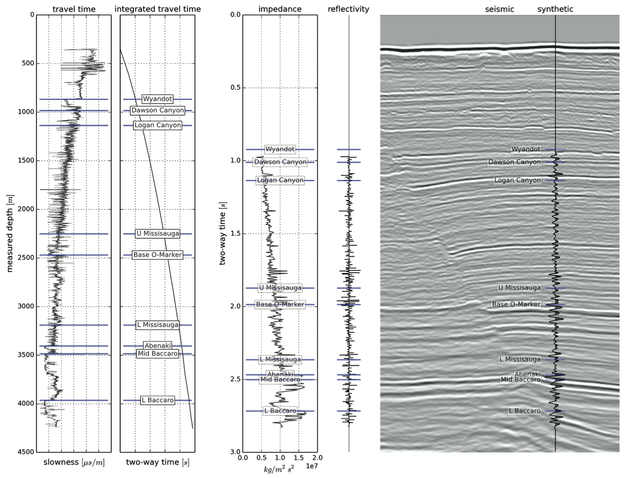















 Except where noted, this content is licensed
Except where noted, this content is licensed