
No more rainbows!
/"the rainbow color map can significantly reduce a person’s accuracy and efficiency"
Borkin et al. (2011)

File under "Aaarrrrrrgghhhhhhh"
The world has known for at least 20 years that the rainbow colourmap is A Bad Thing, perhaps even A Very Bad Thing. IBM researchers Bernice Rogowitz and Lloyd Treinish — whose research on the subject goes back to the early 90s — wrote their famous article Why should engineers and scientists be worried about color? in 1996. Visualization guru Edward Tufte highlighted the problems with it in his 1997 book Visual Explanations (if you haven't read this book, you must buy it immediately).
This isn't a matter of taste, or opinion. We know — for sure, with science! — that the rainbow is a bad choice for the visualization of data. And yet people use it every day, even in peer-reviewed literature. And — purely anecdotally — it seems to be especially rife in geoscience <citation needed>.
Why are we talking about this?
The rainbow colourmap suffers from a number of severe problems:
It's been linked to inferior image interpretation by professionals (Borkin et al 2011).
It introduces ambiguity into the display: are we looking at the data's distribution, or the colourmap's?
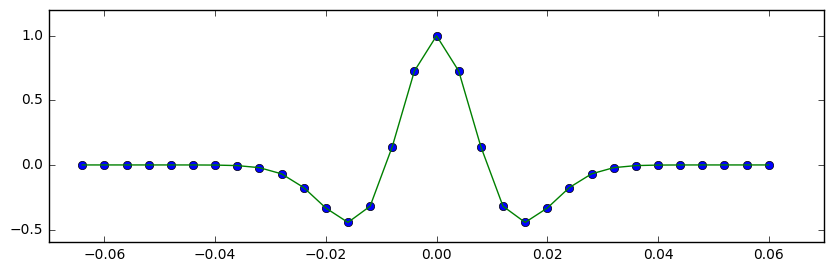
It introduces non-existent structure into the display — notice the yellow and cyan stripes, which manifest as contours:

Colourblind people cannot read the colours properly — I made this protanopic simulation with Coblis.

It does not have monotonically increasing lightness, so you can't reproduce it in greyscale.

There's no implicit order to hues, so it's hard to interpret meaning intuitively.
On a practical note, it uses every available colour, leaving you none for annotation.
For all of these reasons, MATLAB and Matplotlib no longer use rainbow-like colourmaps by default. And neither should you.
But I like rainbows!
People tend like things that are bad for them. Chris Jackson (Imperial, see here and here) and Bert Bril (dGB, in Slack) have both expressed an appreciation for rainbow-like colourmaps, or at least an indifference. Bert went so far as to say he doesn't like 'perceptual' colourmaps — those that monotonically and linearly increase in brightness.
I don't think indifference is allowed. Research with professional image interpreters has shown us that rainbow colourmaps impair the quality of their work. We know that these colours are hard for colourblind people to use. The practical issues of not being readable in greyscale and leaving no colours for annotation are always present. There's just no way we can ask, "Does it matter?" — at least not without offering some evidence that goes beyond mere anecdote.
I think what people like is the colour variance — it acts like contours, highlighting subtle features in the surface. Some of this extra detail is probably noise, but some is certainly signal, maybe even opportunity.
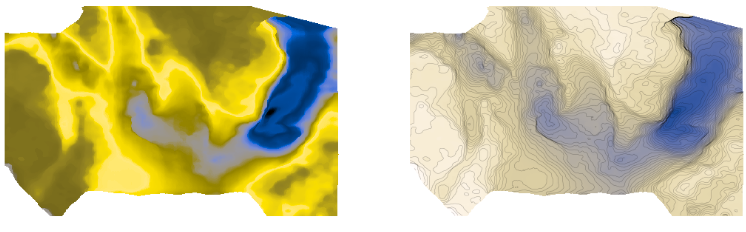
See what you think of these renderings of the seafloor pick on the Penobscot dataset, offshore Nova Scotia (licensed CC-BY-SA by dGB Earth Sciences and The Government of Nova Scotia). The top row are some rainbow-like colourmaps, all bad. The others are a selection of (more-or-less) perceptually awesome colourmaps. The names under each map are the names of the colourmaps in Python's matplotlib package.
The solution
We know what kind of colourmaps are good for interpretation: those that increase linearly and monotonically in brightness, with no jumps or stripes of luminance. I've linked to lots of places where you can read about these — see the end of the post. You already know one perceptual colourmap: the humble Greyscale. But there are lots of others, so let's start with one of them.
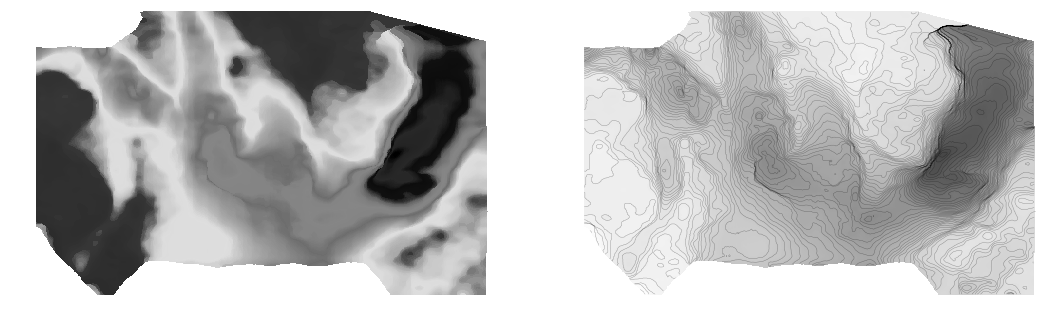
Next, instead of using something that acts like contours, let's try using contours!
I think that's a big improvement already. Some tips for contouring:
Make them thin and black, with opacity at about 0.2 to 0.5. Transparency is essential.
Choose a fairly small interval; use index contours if there are more than about 10.
Label the contours directly on a large map. State the contour interval in the caption.
Let's try hillshading instead:
Also really nice.
Given that this is a water-bottom horizon, I like the YlGnBu colourmap, which resembles the thing it is modeling. (I think this is also a good basis for selecting a colourmap, by the way, all else being equal.)
I must admit I do find a lot of these perceptual colormaps get too dark at the 'low' end, which can make annotation (or seeing contours) hard. So we will fix that with a function (see the notebook) that generates perceptually linear colourmaps.
Now tell me the spectrum beats a perceptual colourmap...

Let's check that it is indeed colourblind-safe and grey-safe:
There you have it. If you care about your data and your readers, avoid rainbow-like colourmaps in the lab and in publications. Go perceptual!
The Python code and data to generate these images is available on GitHub.
![]() Better yet, click here to play with the data right in your browser!
Better yet, click here to play with the data right in your browser!
What do you think? Are rainbow colourmaps here to stay?
References and bibliography
Borkin et al.'s 2011 paper is quite readable.
Read Rogowicz & Treinish's article — it's a classic.
Matteo Niccoli's series of posts, starting with this one.
Peter Kovesi's work on colours is seminal. (And he's a geoscientist!)
Read Ken Moreland on diverging perceptual colourmaps.
Here's viz guru Robert Kosara on why rainbows are rubbish.
You need to know about astronomer Dave Green's work on the cubehelix colourmap.
An extended bibliography from Steve Eddins at MathWorks.
Nathaniel Smith talking about matplotlib's colourmaps at SciPy in 2015.
This post by astronomer Jake VanderPlas is another classic. Listen to this guy.
Still not convinced?
For goodness sake, just listen to Kristin Thyng for 20 minutes:

























 Except where noted, this content is licensed
Except where noted, this content is licensed